
【Google Cloud Next Tokyo ’24】JIG-SAWも講演しました!(AIを活用した障害対応の効率化)
2024.09.13
2024年8月1日~2日の2日間、パシフィコ横浜ノースにてビジネスリーダー、イノベーター、エンジニアのためのクラウドカンファレンス「Google Cloud Next Tokyo ’24」が開催されました。本ブログでは、Google Cloud Next Tokyo ’24に実際に参加したエンジニアから、イベントの様子や講演の現地レポートをいち早くお届けします。
今回は、8/2(金) 15:00~15:30に開催されたセッション「【AI×運用】AIを活用した障害対応の効率化実現方法」をリポートします。
Google Cloud Next Tokyo ’24とは?
Google Cloud Next Tokyo ’24とは、ビジネス リーダー、イノベーター、エンジニアのためのクラウドカンファレンスです。基調講演やスペシャルセッションを含む160を超えるセッション、Google Cloudの最新製品やソリューションをエキスパートと交流しながら体験できるエリアなどが用意されています。
生成AIをはじめ、ビジネスに欠かせないテーマでのセッションなどさまざまなプログラムが2日間にわたって催されました。
JIG-SAWが講演を行いました!
8月2日のDAY2では、クラウドアーキテクトとしてお客様のクラウド活用における技術的な課題を支援する業務に従事する、弊社のアカウントマネジメント本部 本部長 大田原が「【AI×運用】AIを活用した障害対応の効率化実現方法」の講演を行いました。
セッション会場ではもともと用意されていた240席はすべて埋め尽くされ、立ち見の方もいらっしゃいました!

セッション概要
本セッションでは、最新のシステム運用のトレンドをご紹介するとともに、数万ノードのお客様のシステムを運用し日々発生する障害に対峙するJIG-SAWが、AI活用における障害対応の効率化と自動化を行った実例を紹介しました。
システム監視、障害対応の領域においてのAI導入のプロセスやAIで解決できる課題、AIだけでは解決できない課題に対して人の役割と棲み分けのポイントを知ることができる内容となっています。
クラウドネイティブな環境における、システム監視の現在
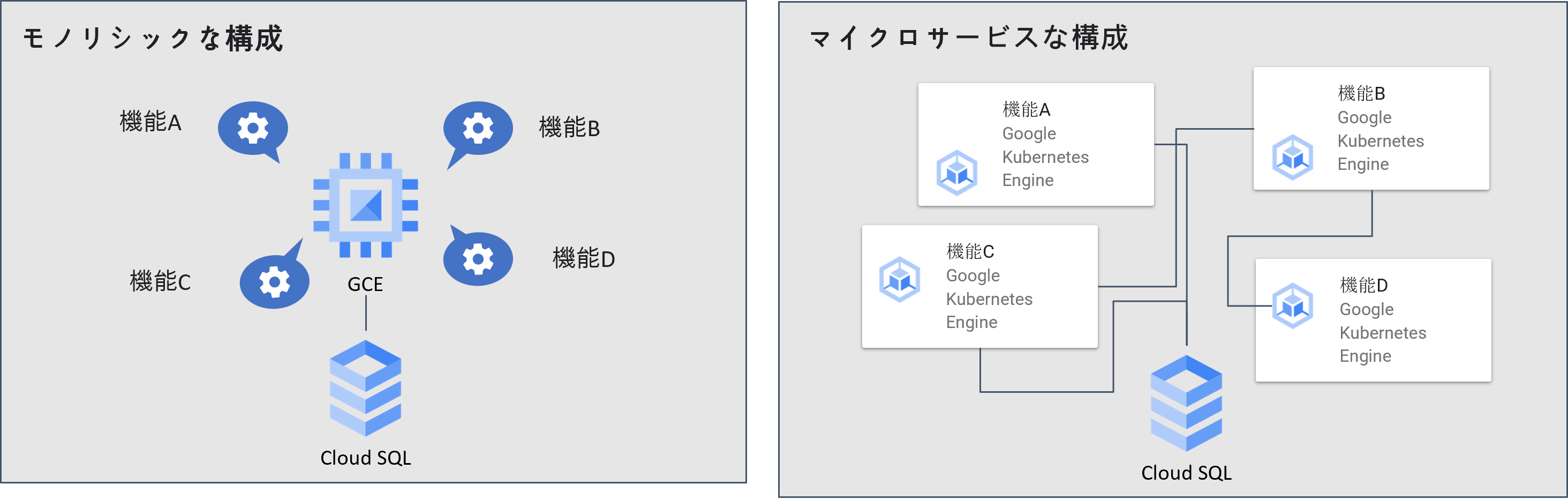
クラウドネイティブな環境におけるシステム構成の最近のトレンドは、コンテナ技術を活用する事が主流(※)になっています。
旧来のモノリシックな構成では、単一のコンポーネントごとに監視を行い障害時は再起動等の対応を行い復旧させた後に根本原因の為のログの調査等を行うのが一般的な監視オペレーションでした。
しかしクラウドネイティブでマイクロサービス化された構成では、複雑な構成や依存関係のあるマイクロサービスの健康状態を監視し、復旧に必要な調査が容易に行える高いオブザーバビリティが必要となります。
| 従来の監視 | クラウドネイティブな監視 |
|---|---|
| 異常発生後の検知 | 異常予兆から検知 |
| 単一のコンポーネントを監視 | システム全体の健康状態の監視 |
| 低いトレーサビリティ | 高いトレーサビリティ |
※ 出展:CNCF SURVEY 2020、CNCF SURVEY 2022、CNCF SURVEY 2023
クラウドネイティブな構成における運用課題
そんなクラウドネイティブな構成における運用ですが、解決すべき課題もあります。
マイクロサービスアーキテクチャによる障害原因の複雑化
モノリシックな構成からマイクロサービス化された構成へ変わっていく中で、冗長性や可用性は高まってきています。その反面、システムはより複雑な構成になってきています。
求められる対応スキルの高度化
障害発生時、モノリシックな構成なら単純に再起動すれば復旧するという事も多々ありましたが、クラウドネイティブな構成の場合はそういはいきません。
障害発生時の原因の特定や復旧プロセスは単純なマニュアル化が難しくなってきており、人のスキルに依存した対応と原因特定や改善の為に高いオブザーバビリティ(可観測性)を求められる場面が増えています。
高いオブザーバビリティを実現するGoogle Cloudのサービス
マイクロサービスアーキテクチャで複雑な構成であっても、システム全体の健康状態をリアルタイムで把握して異常が発生した場合に、詳細な調査が可能なトレーサビリティを実現することが重要です。
Google Cloudでは、以下のような高いオブザーバビリティを実現するサービスが用意されているためこれらの活用も有効です。
| サービス | 詳細 |
|---|---|
| Cloud Monitoring | 収集された指標を使用して、正常性とパフォーマンスのモニタリング、傾向や問題の特定、動作変更の通知を行います |
| Cloud Logging | 収集されたログを使用して、アプリケーションのデバッグと トラブルシューティングを行い、アプリケーションに関する分析情報を取得します。 |
| Error Reporting | 実行中のクラウド サービスで発生したエラーを表示して分析します。 |
| Cloud Profiler | アプリケーションの CPU とメモリの使用状況を分析して、パフォーマンスを 向上させる機会を特定できます。 |
| Cloud Trace | デバッグとトラブルシューティングの際に、アプリケーション リクエストのフローとレイテンシを表示して分析します。 |
AIで解決できる運用課題
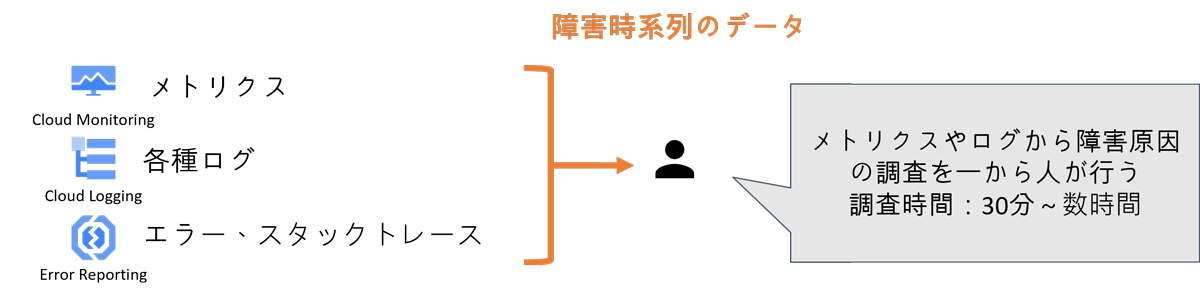
【課題1】障害原因調査に時間がかかる
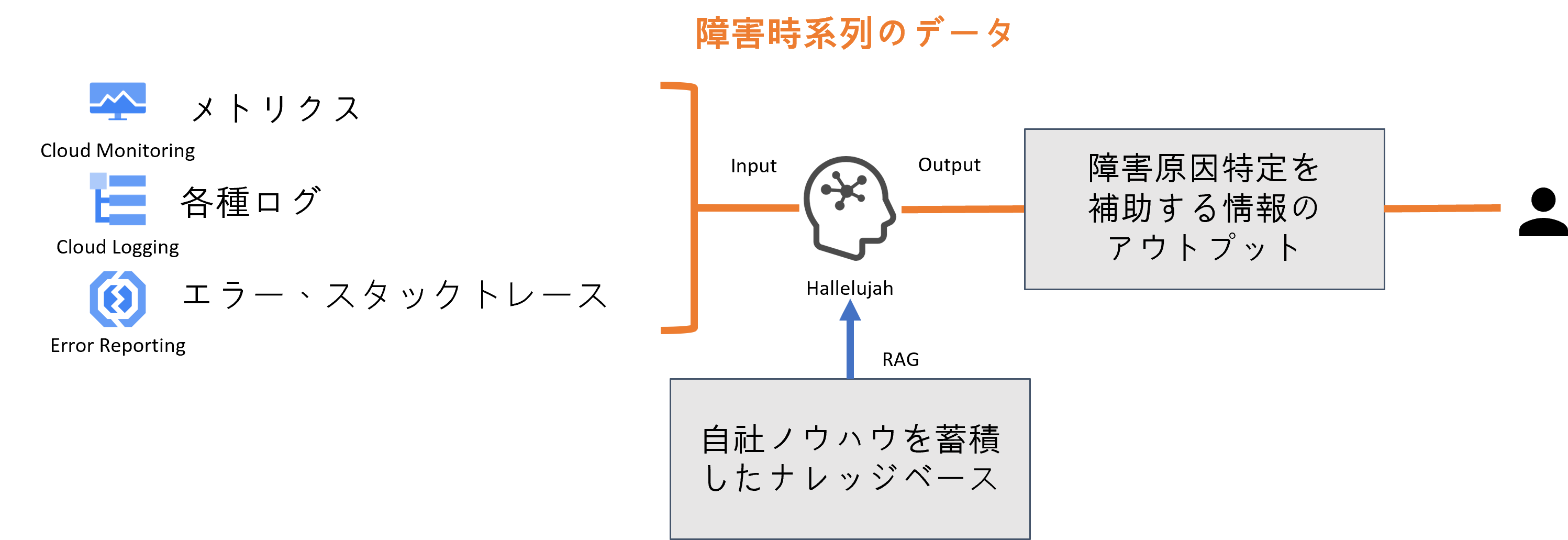
従来の方法では、障害発生時に障害時系列のメトリクスやログやイベントの内容を元に人が一から調査を実施しています。
解決方法
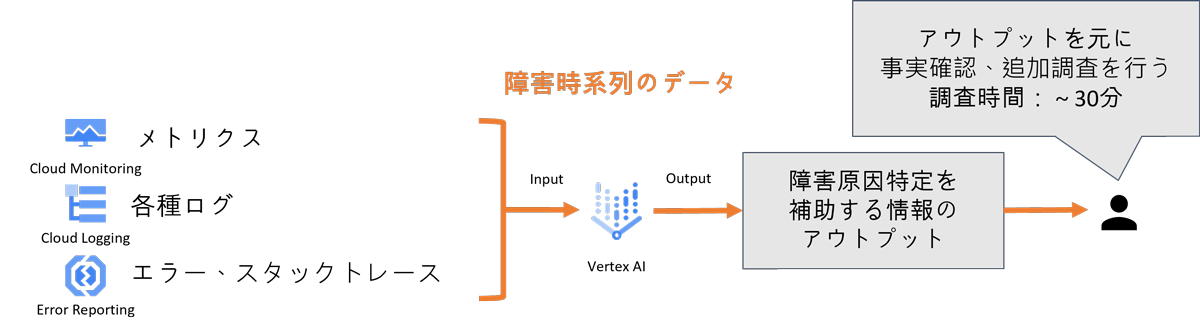
このようなケースの解決方法としては、「障害原因特定をAIが補助し、調査時間を短縮する事」があげられます。
ログや取得可能なメトリクスより、障害の発生原因特定や考えられる事象をAIにインプットしAIからのアウトプットによる情報を障害原因特定の補助的な情報として活用することで、一から人が調査・対応するより効率的に対応を行うことが可能です。
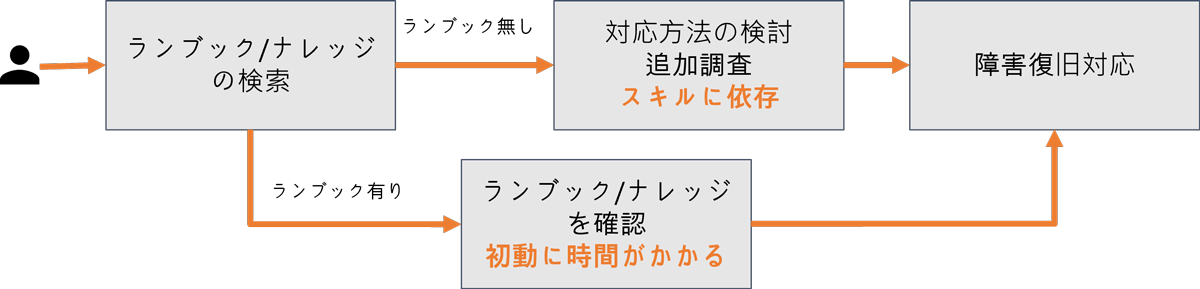
【課題2】ランブック/ナレッジの結び付けに時間がかかる、マニュアル化できずスキルに依存
従来の方法ではランブックやナレッジを検索しオペレーションを開始するのが一般的です。しかし、ランブックやナレッジを結び付けるのに時間がかかったり、ランブックやナレッジがない場合は対応者のスキルに依存した対応が必要となる場合があります。
解決方法
このようなケースの解決方法としては、「AIが対応策を提案し、ランブックの自動提案と対応品質の均一化を図る事」があげられます。
障害原因の取り除きや修復対応の為の対応策をAIに提案を行わせることで、俗人化しない形でスキルの平坦化とインシデント対応の品質を向上します。
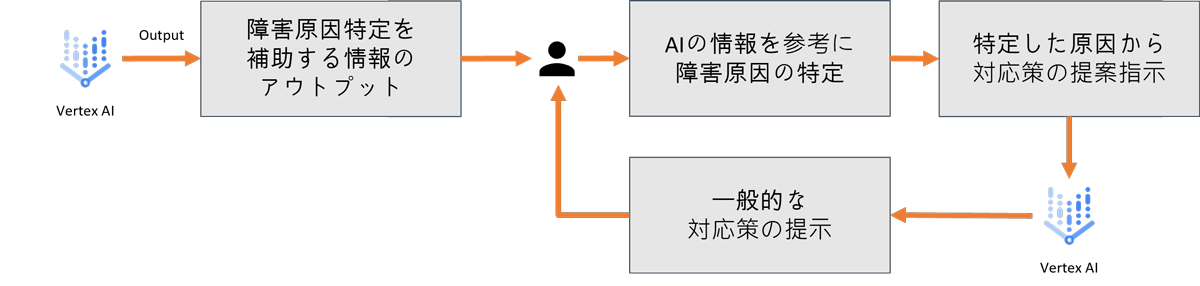
運用×AIの導入事例1. 独自開発のGenAI活用
内外の主要クラウドインフラサービスを中心に、様々なクラウドサービスの 導入支援や監視・運用保守までをワンストップで支援 しているJIG-SAWでは、自社のノウハウでRAGを実行したGenAI(生成的人工知能)「Hallelujah(ハレルヤ)」で障害原因特定と対応策提示を実際のオペレーションで活用しています。
AI導入で解決した課題
AI活用に向けたポイント
運用イメージ
障害が起きた際、原因特定を補助する情報のアウトプットを行った例を記載します。以下は、Tomcatのプロセスダウンを検知しHallelujahで障害原因特定を実施した例です。
|
Tomcatのプロセスがダウンした理由は、メモリ不足(Out of Memory: OOM)によるものと考えられます。以下のログからその根拠を説明します: Aug 1 01:00:00 localhost kernel: Out of memory: Kill process 19634 (java) score 468 or sacrifice child Aug 1 01:00:00 localhost kernel: Killed process 19634 (java), UID 1001, total-vm:7790724kB, anon-rss:4108910kB, file-rss:6822kB, shmem-rss:0kB 詳細な説明 1. メモリ不足の発生 : – ログに「Out of memory」と記載されていることから、システム全体のメモリが不足していたことがわかります。 2. プロセスの強制終了 : – 「Kill process 19634 (java)」とあるように、システムがメモリを確保するためにJavaプロセス(Tomcat)を強制終了しました。 3. メモリ使用量 : – total-vm:7790724kB 、 anon-rss:4108910kB などの情報から、Javaプロセスが大量のメモリを使用していたことがわかります。 仮説 Tomcatが動作しているJavaプロセスが大量のメモリを消費し、システム全体のメモリが不足したため、カーネルがこのプロセスを強制終了したと考えられます。これにより、Tomcatのプロセスがダウンしました。 対策 – メモリの増設 : サーバーの物理メモリを増やす。 – Javaヒープサイズの調整 : Javaのヒープサイズを適切に設定し、メモリ使用量を管理する。 – メモリリークのチェック : アプリケーションコードにメモリリークがないか確認する。 |
この際、アウトプットされた内容を精査してまたナレッジやノウハウを貯めていく事が重要です。AIが強化されより精度の高い回答を出す事に繋がります。
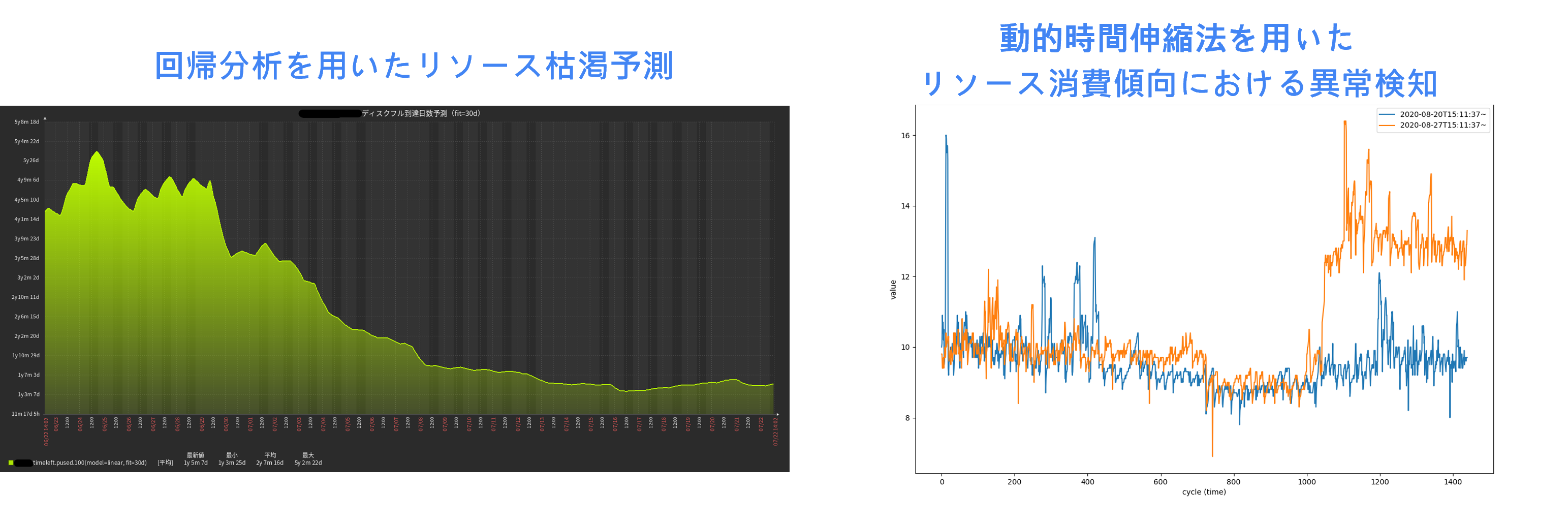
運用×AIの導入事例2. 自社開発のモニタリングツールでAI分析
JIG-SAWでは、自社開発のモニタリングツール「puzzle」で回帰分析や動的時間伸縮法を使ったAI分析でリソース枯渇の予測や予兆、異常の検知を実現しています。
AI導入で解決した課題
AI活用に向けたポイント
AIを運用で活用する際の注意点
AIを運用で活用する際の注意点の1点目は、人が遂行可能”であるオペレーションを整備する事です。AIがなくても人が対応可能なオペレーションとしてフローやルールを整備し、その上でフローやルールにのっとりAIが機能するように導入を進めます。
2点目は、オブザーバビリティ(可観測性)を高める事です。障害原因を特定するのにあたって、特定が可能な情報を正しく取得できていることが重要になります。
まとめ
講演は以上となります。コンテナ技術やサーバレスが主流となりクラウドネイティブな運用が求められる昨今、「高いオブザーバビリティ」×「AI」 でより効率的で品質の高い運用を実現できる事がお分かりいただけましたでしょうか。
課題や注意点をまとめると以下のようになります。
| AIで解決できる運用課題 |
|
|---|---|
| AI活用の注意点 |
|
ここまでお読みいただきありがとうございました!
最後に宣伝ではございますが、JIG-SAWでは国内外の主要クラウドインフラサービスを中心に、様々なクラウド・セキュリティサービスのご案内と導入支援~監視・運用保守までをワンストップで支援しております。

手数料無料でGoogle Cloudを割引価格でご利用いただけるほか、アカウント管理、コスト最適化、技術サポートまでを包括的に支援するサービスもございますので、ぜひお気軽にご相談ください。

【Google Cloud Next Tokyo ‘24】Google Cloud のインフラストラクチャ構成のベストプラクティスを一挙に紹介(講演レポート)

【Google Cloud Next Tokyo ’24】最新の Google Compute Engine(GCE)とTitaniumでハイパフォーマンスとコスト最適化を実現(講演レポート)

【Google Cloud Next Tokyo ’24】CNAPP と SecOps の融合へ:Security Command Center Enterprise によるマルチクラウド セキュリティ(講演レポート)

WindowsイベントログをAmazon CloudWatch Logsに流してみた