
【Google Cloud Next Tokyo ’24】マルチモーダル生成 AI Gemini による映像解析 How-To
2024.08.15
2024年8月1日~2日の2日間、パシフィコ横浜ノースにてビジネスリーダー、イノベーター、エンジニアのためのクラウドカンファレンス「Google Cloud Next Tokyo ’24」が開催されました。本ブログでは、Google Cloud Next Tokyo ’24に実際に参加したエンジニアから、イベントの様子や講演の現地レポートをいち早くお届けします。
今回は、8/2(金) 16:00~16:30に開催されたセッション「マルチモーダル生成 AI Gemini による映像解析 How-To」をリポートします。
Google Cloud Next Tokyo ’24とは?
Google Cloud Next Tokyo ’24とは、ビジネス リーダー、イノベーター、エンジニアのためのクラウド カンファレンスです。
基調講演やスペシャルセッションを含む160を超えるセッション、Google Cloudの最新製品やソリューションをエキスパートと交流しながら体験できるエリアなどが用意されています。
生成AIをはじめ、ビジネスに欠かせないテーマでのセッションなどさまざまなプログラムが2日間にわたって催されました。
セッション概要: マルチモーダル生成 AI Gemini による映像解析 How-To
今回は、8/2(金) 16:00~16:30に開催されたセッション「マルチモーダル生成 AI Gemini による映像解析 How-To」をリポートします。
公式サイト上のセッション紹介は以下の通りです。
“AI による利活用が進みづらかった動画・映像ファイルも、マルチモーダル AI の進化により今後、より処理の自動化が進むと思われる。
ただし、単純に動画ファイルを生成 AI に解析させても動画という特殊メディアゆえに思うような結果が得られなかったり、動画を解析する以外の利活用のイメージが湧かなかったりすることで、利活用が進まない可能性がある。
このセッションでは、より多くの企業が動画も含めた非構造化データの利活用を推進できるための、Gemini による映像解析におけるベストプラクティスをご紹介します。”
登壇者
| 企業 | 名前(敬称略) | 役職・肩書 |
|---|---|---|
| Google Cloud | 段野 祐一郎 | カスタマー エンジニアリング カスタマー エンジニア |

セッション詳細
みなさんは「マルチモーダル生成AI」というものをご存じでしょうか。
マルチモーダル生成AIとは、文字だけでなく、画像や動画など異なる種類の情報を扱うことができるAIの事です。
今回は、Googleが開発した最新マルチモーダル生成AI、Geminiを使った映像解析に関するセッションについてのレポートになります。
アジェンダ
Googleマルチモーダル生成AI
Geminiの説明に入る前に、映像解析に求められるニーズや、その実現の困難さが説明されました。 映像解析には、以下のような機能が求められるようです。
| 解析処理 | ユースケース |
|---|---|
| 要約・分類 | 動画内容の要約、タイトル付け、レコメンド・検索用のメタデータの生成 |
| キャプション付け | 動画内容の理解、レビュー |
| 文字起こし | 字幕/closed captionの作成、映像と合わせた会議内容の文字起こし |
| チャプター ハイライト作成 | YouTube動画のチャプター作成、スポーツのハイライト動画作成 |
| 考査 | 誤字チェック、表現を社内/業界基準に準拠 |
| 状態検知 | 在庫把握、異常検知、混雑チェック |
| 行動検知 | スポーツのアクション判定、侵入検知 |
などの理由から、従来の画像解析AI+音声解析AIの組み合わせだと実現が困難でした。
 これらのニーズに対し、比類のない機能を提供するプラットフォームとして、今回Geminiが紹介されました!
これらのニーズに対し、比類のない機能を提供するプラットフォームとして、今回Geminiが紹介されました!
Geminiとは
Geminiの特徴として下記3点が挙げられていました。
今回のセッションではマルチモーダル生成AIのラインナップとして、「Gemini 1.0 Pro Vision」、「Gemini 1.5 Flash」、「Gemini 1.5 Pro」という計三つのモデルが紹介されていました。
それぞれのモデルの特徴
| Gemini 1.0 Pro Vision | |
|---|---|
| Gemini 1.5 Flash | |
| Gemini 1.5 Pro |
こういったモデルの中から利用したいものを選んで使うことが可能です。
それぞれにしっかり個性があり差別化されているので、自分や会社に合ったモデルを選ぶことが重要そうだと感じました。
映像データの準備、注意点
この章では、モデルごとのサポートフォーマットやGemini利用上の留意点が解説されました。
利用可能な映像データ
モデルごとの処理可能な映像の尺(時間)は以下の通りです。
| Model | 動画尺 | 音声尺 |
|---|---|---|
| Gemini 1.0 Pro Vision | 2分 | ×(音声は非対応) |
| Gemini 1.5 Flash | 1時間 | 8.4時間 |
| Gemini 1.5 Pro | 音声なし1時間、音声あり45分 | 8.4時間 |
また、サポートフォーマット は以下の通りです。
| Video MIME type | Gemini 1.0 Pro Vision | Gemini 1.5 Flash | Gemini 1.5 Pro |
|---|---|---|---|
| FLV – video/x-flv | 〇 | 〇 | 〇 |
| MOV – video/mov | 〇 | 〇 | 〇 |
| MPEG – video/mpeg | 〇 | 〇 | 〇 |
| MPEGPS – video/mpegps | 〇 | 〇 | 〇 |
| MPG – video/mpg | 〇 | 〇 | 〇 |
| MP4 – video/mp4 | 〇 | 〇 | 〇 |
| WEBM – video/webm | 〇 | 〇 | 〇 |
| WMV – video/wmv | 〇 | 〇 | 〇 |
| 3GPP – video/3gpp | 〇 | 〇 | 〇 |
これだけのフォーマットに対応している上に、対応していなくてもトランスコードすれば利用できるので、様々なニーズに対応できそうです。
Geminiを利用する上での留意点
Geminiで映像解析を行う際に気を付けたい点として、以下が挙げられていました。こういった特性を理解し、効率的にGeminiを使いこなしていきましょう!
動画は1fps(1秒1フレーム)としてサンプリング処理される
インプット可能なのは最大10動画まで
例)プロンプト:生成AIへの指示文 「この動画の内容を簡単に説明して!」
文字起こしに句読点は含まれず、音声以外の音の文字起こしは不得手
プロンプトエンジニアリングの重要性
プロンプトエンジニアリングとは、生成AIに期待通りの出力をさせるために、指示文(プロンプト)を設計・改良する技術を指します。
プロンプトの書き方で性能が大きく変わるという研究結果もあります。
また、AIから期待した回答が返ってこないのは、このプロンプトが原因なことも多いそうです。例えば、「三角と円を書いてください」と指示されたとします。結果はきっと大きさや配置など、人それぞれになると思います。
これは、映像解析においても同じで、指示は明確で具体的にする必要があります。
Google社のこちらの動画(Google Pixel:旅も、Google Pixel と 篇 feat. 小松菜奈)をGeminiに説明してもらった例が以下になります。

 このように、プロンプト改善によって出力して欲しい情報を引き出すことが可能です。
このように、プロンプト改善によって出力して欲しい情報を引き出すことが可能です。
構造化プロンプトの活用
プロンプトエンジニアリングの重要さを知っていただけたと思うので、具体的なプロンプトの記載方法をご紹介いたします。プロンプトに記述すべき項目は決まっていることが多い為、テンプレートを用意、利用することが推奨されています。今回は具体例として、下記形式の構造化プロンプトが紹介されていました。
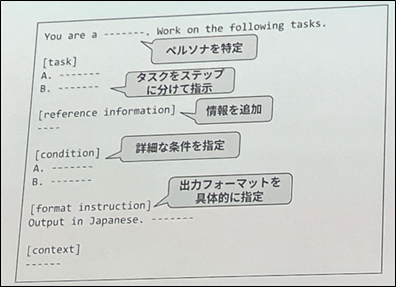
構造化テンプレートを利用する際のポイント
構造化テンプレートを利用するメリット
プロンプト実装のステップ
複雑な指示をしたい場合、最初から難しい指定をしてしまうと求める結果は得られないことが多いです。
プログラム開発と同じように、シンプルな内容から初めて出力結果を見ながら徐々に指示を追加していく必要があります。
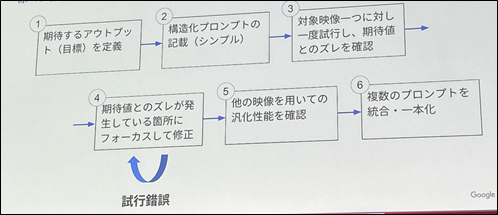
複雑なプロンプトを実装する上で効果的な手法が3点紹介されていたので、記載していきます。
映像分割
期待するアウトプットを得るには、長い一本の映像をそのまま処理するのではなく、細かく分割し、それぞれに最適なプロンプトを探っていくのが効果的です。
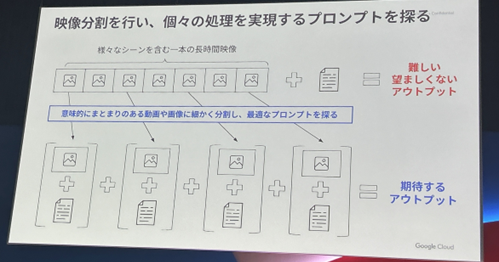
修正の度に毎回関係のないシーンを処理する必要がなくなるので、コストも時間も削減できるというメリットもあります。
中間結果の出力
タスクが複数ある場合は、各ステップの結果をそれぞれ出力することで、ステップごとの処理結果が確認できます。
これによりどこのステップまで理想的に動いているかが分かります。(ただし、出力内容が増えるため出力結果が変動する可能性があります。)
プロンプト管理
プロンプトの内容を試行錯誤する際は、過去に試したプロンプトとの比較が必要です。Vertex AIコンソールを使うことで同名のプロンプトを複数保存できます。
こちらは、モデルのバージョン、実行時のパラメータも保存されるため、過去の履歴を簡単に再現できます。

このような手法を駆使しつつ地道に試行錯誤するのは大変そうですが、実装したかった通りのアウトプットが返ってきたときの達成感はすごそうだなと感じました。
動画から情報を引き出すプロンプト
ここでは動画解析ならではのプロンプト例とノウハウについて解説されました。便利な方法がいくつも解説されていましたので紹介していきます。
動画サマリーの生成
この動画(Google Pixel 8 : リアルタイム翻訳篇)の「サマリー」と言っても、動画そのものの説明なのかストーリーの説明なのかなど、どのような観点で情報をまとめたいかは場合によって異なります。
そんな時はこんな聞き方をしてみましょう。

また、「3センテンス以上に要約して」、「可能な限り詳細な説明をして」など出力テキストの長さを調整することも可能です。
複数の情報を取得
タスクを複数に分割することもできます。
以下は「動画をシーンに分割する処理」と「内容を説明する処理」に分割しているプロンプトです。
音声の文字起こし
この方法を使えば、文字起こしをする際に登場人物を特定し名前を付けて出力することができます。

シーン数の調整
ここでは動画をシーンごとに分割して記述する方法が2つ紹介されました。
分割するシーンを単純に指定する方法
例)「タイムスタンプ付きで、4つのシーンに分割」
シーンを細かく分割し、それを指定のシーン数に統合する方法
例)
「似たシーン」や「あらすじ」などの可変なものを基準としてまとめることができます。
画像によるFew-shotプロンプティング
画像に対する補足情報をプロンプトに埋め込むことで、追加学習を行わずに知識獲得が可能です。

画像にない情報を補完させない
有名なキャラクターや人物は、Geminiが賢いばかりにキャラクター名など画像にない情報を勝手に補完してしまうことがあります。
これは、Geminiに特定の名詞を利用するのを避けるよう指示することで解決します。

肯定形の方が良いとされている理由は、肯定系で記載されている学習データが多いため、否定形では求めた結果が返ってこないことがあるからだそうです。
以上、これらが紹介されていました。筆者としては、Geminiに追加で知識を与えてあげることができる「画像によるFew-shotプロンプティング」がとても感動しました。
Ask the Speaker
最後に、登壇者の方に質問できる機会を頂いたので
「初学者はどんなことから始めるべき?」
ということをお聞きしてみました!回答は以下になります。
今回のセッションは企業向けなので、いきなり初学者がGeminiを使った業務改善を考えるのは難しいと思います。
なので、まずは身の回りの事を便利に出来ないか、Geminiを使って遊び感覚で試してみるのがいいと思います。
Geminiのスマホアプリがあるので、まずはそれを触ってみて、Geminiってどんなことが出来るのか、どんなプロンプトの書き方をすれば思った結果が出せるのか、などを知っていくのが大事なのではないでしょうか。
との事でした!
Gemini活用の例として、登壇者の段野さんは最近、実際にGeminiを使って忘れ物チェッカーを作ってみたと仰っていました。
Geminiに「あなたは忘れ物点検係です」と役職を与え、出かける前と帰宅後の荷物を並べた写真を見せることで、帰宅後になにが不足しているのか答えてくれるそうです。
これなら確かにGemini初心者でも楽しんで学ぶことができるなと感じました。筆者も今回教えて頂いたように、「まずはGeminiで遊んでみる」ということを実践してみようと思います。
まとめ
今回はGeminiを使った映像解析についてのセッションでした。録画した会議の内容を簡単にまとめたり、動画を尺内に収めたりなど業務に活かせそうなことが盛りだくさんでしたね。
皆さんもGeminiの新しい使い方、業務改善を試してみてください!
最後に宣伝ではございますが、JIG-SAWでは国内外の主要クラウドインフラサービスを中心に、様々なクラウド・セキュリティサービスのご案内と導入支援~監視・運用保守までをワンストップで支援しております。

手数料無料でGoogle Cloudを割引価格でご利用いただけるほか、アカウント管理、コスト最適化、技術サポートまでを包括的に支援するサービスもございますので、ぜひお気軽にご相談ください。




