
クラウドでも災害対策!継続した自社サービスを提供するためのDR環境
2021.09.10
オンプレミスと同様、クラウドでもデータセンターの障害や災害でサービスが停止するリスクは存在します。
使用しているリージョンがサービス断となった場合でも、他のリージョンにDR(Disaster Recovery)環境を準備しておくことで、できるだけ早く、できるだけ最新の状態で自社サービスを再開・継続させることができます。
本記事では、継続したサービス提供が求められる全事業者に向け、DR環境の考え方と導入案をご説明しています。
はじめに
AWSをはじめとしたクラウドサービスが急成長したことで、クラウド上で継続したシステムを運用している企業が増えてきました。 停止が許されないようなシステムでは、インスタンスやデータセンターに障害があってもサービスを継続するために冗長構成を取ることが普通です。
多くの場合、単一リージョン内にて複数のアベイラビリティゾーン(AZ)にインスタンスを配置することで冗長化が実現されます。 しかし、もしリージョン全体が停止するような災害や大規模障害、あるいは大規模なセキュリティ攻撃が発生したら、そして、もしそのような状況下でも継続しなければならないサービスであったとしたら…。
今回は、そんな「まさかの事態」に備えるためのDR環境についてご紹介したいと思います。 前半はDR環境の考え方や重要性、後半はAWSでのDR環境構築を実現する方法と留意点について説明します。
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら

DR(Disaster Recovery)の概要
DR(ディザスタリカバリ)とは?
DRは、名前の通り「災害時の復旧」を意味します。 企業のコンプライアンス要件としては、BCP(Business Continuity Plan; 事業継続計画)の一部として規定されていることがあります。 災害発生時に継続して事業を展開する、いわばBCPを実現するための復旧作業、という位置付けです。
システムのバックアップデータを別の場所(AZ、リージョン)に保管しておく、といったことだけでもDRに向けた取り組みとなりますし、ほとんどのシステムで行われていることと思います。 ただ、システムダウンによる損失をできるだけ抑える、そもそもシステムダウンが許されない、という観点だと、システムを可能な限り継続させるためのDRの取り組みは非常に重要なものとなります。
DRの必要性
クラウドは名前の通り実体が見えない雲のようなイメージですが、現実としてクラウドサービスを提供しているサーバは存在しますし、リージョンにはAZの数だけデータセンターが存在します。 オンプレミスと違い、物理的に離れた場所でも冗長化がしやすい、自社でのサーバ管理が不要、といった利点はありますが、それで絶対安心、というわけにはいきません。
たとえば、大地震や台風によってリージョン内の全AZが機能不全に陥る可能性は十分考えられます。 データセンターそのものが災害に強い構造であっても、電源や通信などいずれかが断たれてしまえばサービスは止まってしまいます。 こういったときに、地域レベルで離れたリージョンにサービスが展開してある/展開できると「転ばぬ先の杖」となることでしょう。
DRは、ランサムウェア攻撃などサイバー攻撃にも有効
自然災害だけでなく、サイバー攻撃、特にランサムウェア攻撃(身代金要求型ウイルス)に対してもDRは有効です。
2016年頃から流行したランサムウェア攻撃では、環境全体を暗号化されてしまうと、個々にバックアップを取っていたとしてもシステム全体が復旧できない、そもそもバックアップも暗号化されてしまい手も足も出ない、といった事態が起こり得ますし、実際に起きています。
以前の記事(https://ops.jig-saw.com/tech-cate/cloud-security)でも紹介したIPAの「情報セキュリティ10大脅威2021」でも、ランサムウェアによる被害が組織の脅威第1位になっていますね。非常に恐ろしいサイバー攻撃ですが、本番環境と異なるネットワーク、異なるリージョンで、暗号化されていないデータから環境全体を復旧させることができれば、最小限の影響でやり過ごすことができます。
なお、ランサムウェア攻撃は大企業、中小企業、個人のいずれもターゲットになる可能性があります。特に規模が小さい組織やシステムでこそ、セキュリティ対策や攻撃への備えを十分に講じておく必要があるのです。
DR、オンプレとクラウドどちらで構築すべき?
いざDR環境を構築するとなった際、オンプレミスでは遠く離れた地に赴いて機器やネットワークを配備した後、定期的に通ってメンテナンスをしなければならなくなります。複数拠点があり、それぞれで設備と人員が確保できる企業であればいいのですが、それほど多くはないでしょう。
それに対し、クラウドではどこからでも世界中にデータや環境を配備することができ、設備のメンテナンスも不要なので、利用しない手がありません。 使った分しかコストが発生しないので、ちょっと使って検証してみるのもアリです。規模に応じていつでも拡張縮小できますし、いつでもやめることができます。
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら
DR環境設計時の考え方
RTOとRPO
いざDR環境を構築しよう!…となる前に、とても大事なことがあります。
対象のシステムが
(a) どの程度サービス停止を許容できるか
(b) どこまでのロールバックが許容されるか
を把握した上で、環境を設計しなければなりません。
前者(a)をRTO(Recovery Time Objective;目標復旧時間)、
後者(b)をRPO(Recovery Point Objective;目標復旧時点)と呼びます。
この2つの指標を確実に抑えておきましょう。
4つの設計方針
DR環境設計における代表的な考え方を4つ紹介します。
ホットスタンバイ
現行のシステムを別の場所に常時レプリケートしておき、丸々同様の環境を用意しておくことで、DR発動時に素早く移行する。絶対にサービスを止められないミッションクリティカルなシステム向け。
ウォームスタンバイ
ホットスタンバイと同様に環境を常時レプリケートしておくが、スペックをある程度縮小しておくことでコストをやや抑える。復旧までの時間が少々増加するが、巻き戻りをさせたくないシステム向け。
パイロットライト
システムのコア部分のみを最小スペックで別環境に維持しておき、DR発動時に一部のみすぐ展開、徐々に環境全体を復旧させる。環境全体の早期復旧は必要ないが、最低限のサービスは継続しておきたいシステム向け。
バックアップ&リストア
システムのバックアップを別の環境にコピーしておき、DR時にはそれらをリストアすることで環境を展開する。DR環境の維持コストを抑える代わり、サービス停止がある程度許容されるシステム向け。
4つの設計方針のまとめ

対象のシステムに一番近い考え方はどれかを照らし合わせることで、どういったDR環境を構築すればいいのかが見えてくるのではないでしょうか。
ちなみに、上に述べたものほど維持コストが高くなるため、その観点でのトレードオフも必要です。
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら
AWSのインスタンスをDRで展開させる
「考え方は分かったけれど、どうやってDR環境を構築すればいいの?」 となったところで、実際にAWS上にてDR環境を実現するための事例をいくつかご紹介します。
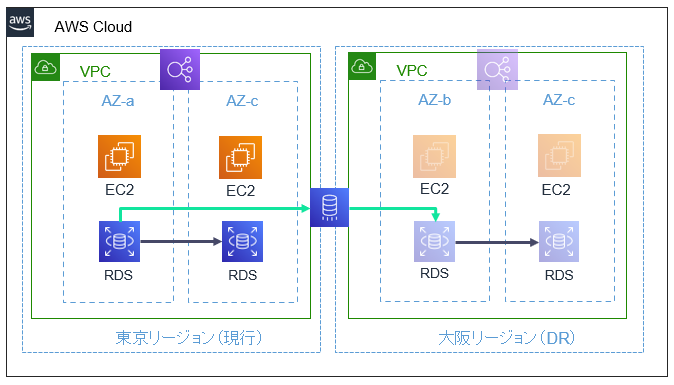
今回は、東京リージョンで稼働しているEC2とRDSのインスタンスがメインとなるシステムについて、DR環境を大阪リージョンに構築する、という前提とします。非常にシンプルな構造ですが、このような感じです。
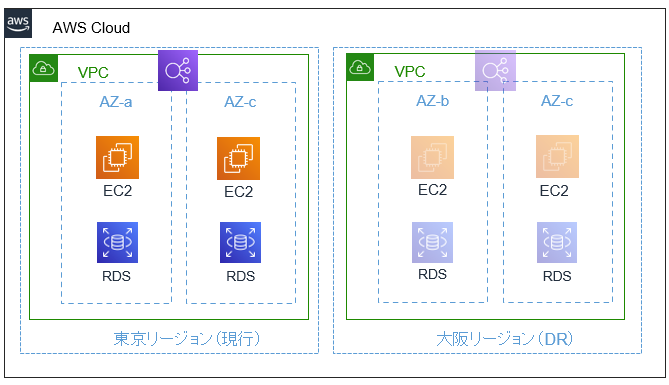
別のリージョンを使用する/している場合は、AWSの機能やサービスが対応しているかを必ず確認しましょう。 (逆に東京→大阪で不可能、他リージョンでは可能といったものもあるかもしれません)
また、いざDRを発動するという時は、当然ながら緊急事態ですので、「誰がやっても簡単にできる」手順であることが望ましいです。手順書を整備しておきましょう。
EC2インスタンスの場合
ここでは「ホットスタンバイ」および「バックアップ&リストア」に対応した2例をご紹介します。
ホットスタンバイでは、rsyncやDRBDなどの同期ツールを用いてリージョン間でEC2インスタンスの中身を継続的にレプリケートするという作戦です。
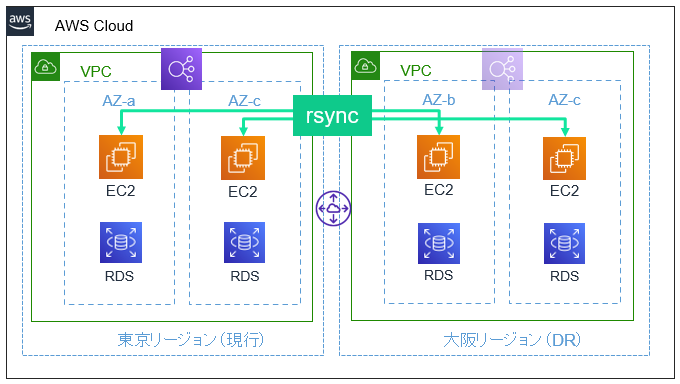
常に同じ状態が保たれるため、DR発動時には接続先を変える(WEBの場合、Route 53などDNSの向きを変える)だけ!Route 53のフェイルオーバー機能を設定しておけば、現行環境が停止した際に自動で切り替えることも可能です。(RDSなど別のリソースもホットスタンバイさせておく必要があります)
フェイルオーバーにはGlobal Acceleratorといった、ロードバランサの上位に配置され、リージョンを跨いで利用可能なサービスも活用できるので、確認してみてください。
難点として、常に稼働しているということはそれだけのコストが発生します。本番環境と全く同じ構成をレプリケートすると、単純に本番環境もう1つ分利用料がかかってしまうということです。
そこで、ウォームスタンバイ方式でインスタンスサイズを小さめで作成しておき、適当なタイミングで同じサイズにする、パイロットライト方式でレプリケートするインスタンスを主要なものに絞る、といったコスト面でのトレードオフを検討する必要が出てくるわけですね。
なお、リージョン間のレイテンシが数秒単位でRPOに影響しますので、継続的な同期を行う場合は物理的な距離の近さもリージョン選定時に考慮しなければなりません。
バックアップ&リストアでは、定期的に取得しているバックアップを大阪リージョンへコピーするよう設定しておき、DR発動時にリストアすることで展開します。
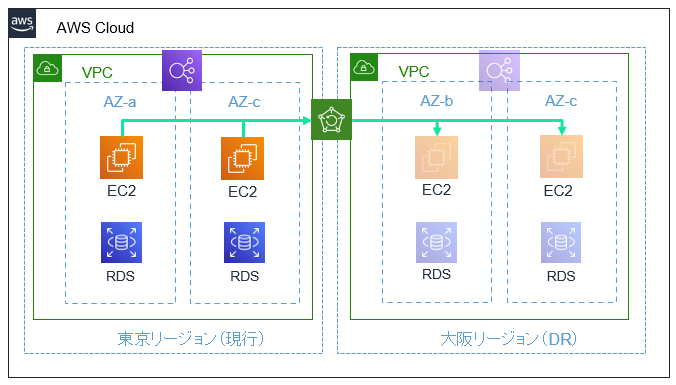
DR時にインスタンスが作成されるため最小限のコストで済みますが、緊急事態にいちいちインスタンスを1台ずつリストアするのは正直かなりの手間です。そこで、CloudFormationであらかじめテンプレートを作成しておくことで、ワンアクションで簡単に複数のEC2やロードバランサなどのリソースを構築することができます!
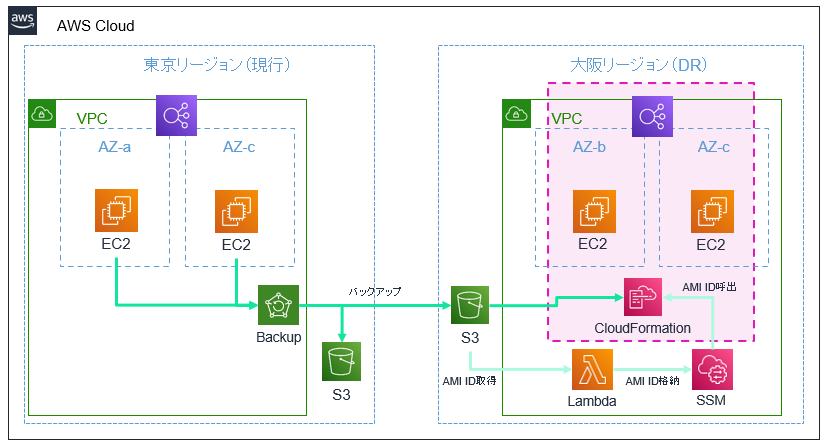
LambdaとSystems Managerを組み合わせて最新のバックアップからEC2を作成する、といった工夫もできるので、準備の手間やテンプレートの形式(JSONまたはYAML)に慣れるといった難点はあるものの、CloudFormationはこういったDR用途では高い効果を発揮します。CloudFormationの役立つ活用方法は他にも様々ありますので、少し触ってみて慣れておくのも良いでしょう。
ここで紹介したもの以外に、AWSでは「CloudEndure DisasterRecovery」というサービスが用意されています。こちらもご確認頂き、どの事例が自社システムで好ましいか検討してみてください。
RDSインスタンスの場合
EC2と同様に、「ホットスタンバイ」および「バックアップ&リストア」に対応した2例をご紹介します。
ホットスタンバイでは、データベース移行サービスであるDMS(Database Migration Service)による継続的レプリケーションを利用します。
DMSでは継続的レプリケーションの手段としてCDC(Change Data Capture)というプロセスが用いられており、データベースへの変更を常に監視し反映することでレプリケート先のデータベースを最新の状態に保つことができます。
参考サイト: AWS DMS を使用した継続的なレプリケーション用のタスクの作成(AWS 公式サイト)
DR発動時点ですぐに使える状態のデータベースが用意されているのは大きな強みですが、RDSの料金、DMS専用として作成されるインスタンスの料金が発生することから、維持がかなり高額となってしまうのが難点です。
また、DMS CDCのパフォーマンスの問題から、レプリケート先のインスタンスタイプを下げることは推奨されていません。リージョン間の距離に伴うレイテンシにも注意を払う必要があります。
バックアップ&リストアでは、RDSに備わっているクロスリージョン自動バックアップを活用します。現在使用中のRDSの設定画面で「別のAWSリージョンへのレプリケーションを有効にする」にチェックを入れ、送信先と保存期間を指定するだけ!
DR時にはレプリケート先のリージョンで「特定時点への復元」を実行することで、ポイントインタイムリカバリの方式でRDSを展開することができます。 復元可能な時点(RPO)はなんと障害発生の5分前まで!定期バックアップとトランザクションログを組み合わせることで、バックアップ&リストアの方式にしてはかなり短いRPOを実現しています。
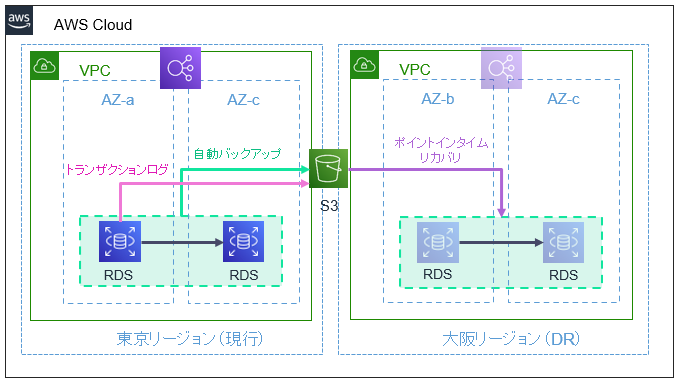
注意点として、記事執筆時点では送信先リージョンが限られていたり、SQL Server利用の場合は暗号化した状態でのレプリケーションに対応していなかったりするため、利用を検討する際は対応状況を確認しましょう。また、新しくインスタンスを作成してリカバリを行うこととなるので、データベースの規模に応じて完了までに数分~数時間かかることを考慮する必要があります。
参考サイト: 別の AWS リージョンへの自動バックアップのレプリケーション(AWS 公式サイト)
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら
要注意!DR環境構築でハマるポイント
ここでは、DR環境の構築を行うにあたって、実際に設計や検証を行った経験から、あらかじめ考慮しておかなければならないことについてピックアップしてご紹介します。
DR先のリージョンで対応していないサービスがある
大阪などの新しいリージョンでは未対応のサービスがいくつかあります。記事執筆時点ではDirectory Serviceの一部やCognitoなど。使っているサービスが提供されているかは、AWS公式「AWS リージョン別のサービス」より確認できます。
もしも大阪リージョンで対応していないサービスを使っている場合は、代替手段を検討するか、シンガポールなど少し離れたリージョンも候補にしましょう。利用可能なサービスは文字通り日々更新されていくため、ニュースリリースや↑のページをこまめにチェックするのもアリです。
DR先のリージョンで対応していないインスタンスタイプがある
特に複数AZでEC2を冗長化している際に気を付けなければいけない点です。
大阪リージョンなど、1つのAZでしか使用できなかったり、そもそも対応していなかったりするインスタンスタイプがいくつか存在します。たとえば、t2やm4など前世代のものはap-northeast-3aのみで提供(つまり冗長構成が組めない)、t4gやm6gなどのGraviton2, t3aなどのAMDは非対応、といった具合です。
「この機会にt2からt3へ上げちゃおう!」と思った方、そのまま上げてしまうと起動しなくなる可能性があるので気を付けてくださいね。詳しくは以下をご覧ください。例えばt2からt3へは、拡張ネットワークに対応するためにENAドライバのインストールが必要です。
参考サイト:インスタンスタイプを変更する
Windows Serverを複製するときに気を付けること
Windows ServerはマシンSIDなどの固有情報をインスタンスごとに保有しています。同じネットワーク、同じドメインで同じ固有情報を持つインスタンスが複数存在する場合、競合によりインスタンスが起動しないことが起こり得ます。
本記事ではDR発動の想定なため、VPCピアリングをしていない限り同じネットワークで同一の固有情報を持つインスタンスが起動することはありませんが、お使いのアプリケーションやドメインによっては固有情報の競合による問題が発生する可能性があります。
本来、EC2上のWindows Serverを複製する際には、固有情報を初期化するsysprepというツールを用いて設定を行うことが推奨されています。 要は、別ネットワークでインスタンスを複製し、一度sysprepを実施して固有情報を初期化した状態で、再度AMIを作成する、といった手順です。
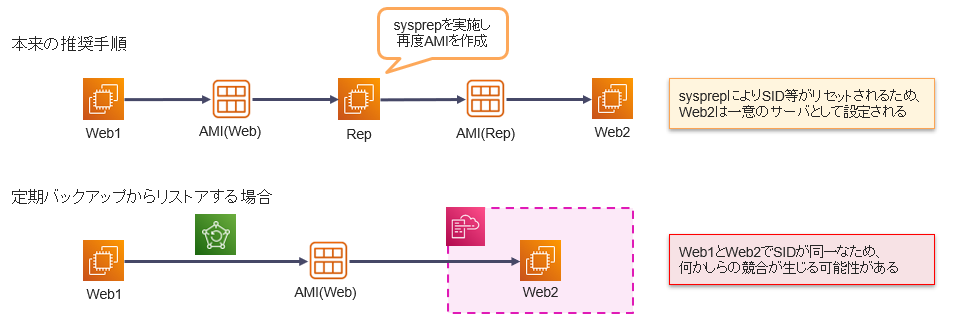
DR発動時に定期バックアップからのAMIを用いて手動またはCloudFormationでEC2インスタンスを複製する場合はsysprepされていないインスタンスを使用することになり、競合の懸念が生じますが、日次のバックアップから毎日sysprepを実施済みのAMIを用意するのはあまり現実的ではありません。かといってDRの手順にsysprepを含むと、sysprep実施に伴う再起動でRTOは増加してしまうし…。
競合による影響評価、日々の作業量、EC2のバックアップ頻度(RPO)、DR時の作業量(RTO)など様々な要素を考慮して検討を行いましょう。
ライセンスや自動起動のエージェントは大丈夫?
自動で起動してデータを収集、その結果を別のサーバに伝達するエージェントが存在するインスタンスの場合、自動起動がオンになっていると複製して起動した直後に既存インスタンスとの競合が発生します。 またセキュリティソフトであるDeepSecurityなどではライセンス情報が上書きされてしまうため、Manager上で既存インスタンスの無効化を行うなど対処が必要です。DR発動時には余裕がないことが想定されるので、あらかじめライセンスの移行に関して手順化しておく、バックアップ作成前にエージェントの自動起動をオフにするなど競合しないような対策を講じておきましょう。
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら
まとめ
DR環境の意義と考え方、そして実際にDR環境を構築する際の事例を紹介させて頂きました。
CloudFormationなど、DR時に限らず活用できて役立つサービスも多くありますので、ちょっと触ってみて使い方に慣れておくのも良いかと思います。また、防災訓練のような形で、定期的に障害を仮定したゲームデーを設けてDRやBCPの有効性を確かめることも大切ですね。
正直、考慮しなければいけないことが多く、DR環境の作成は思ったより大変かと思います。それでも、実際に災害が発生したときに方針も準備も万端な状態というのはかなり心強いです。ぜひ、今からでもDR環境の検討をしてみてください!
最後に宣伝となりますが、日常のシステム監視・運用は当社にお任せしませんか?
DRは大規模な障害やサイバー攻撃への対策となりますが、通常時でもシステムの異常をリアルタイムで監視、検知することで、システム内部起因の不具合や障害を未然に防ぎ、サービスのダウンタイムを抑えることができます。
当社では システムを24時間365日監視・運用するサービス を提供しております。自社での負担を軽減したい、営業時間外でもサービスが継続して提供できるよう体制を整えたい、といった企業のご担当者様など、ぜひご相談を頂ければと思います。AWS、Google cloudを当社でご契約いただいた場合「サイバーリスク保険」も無償付帯しているため、万が一の場合も安心です。
最後までお読み頂き、ありがとうございます!
> システムの障害を検知・普及「監視運用代行サービス」詳細はこちら




