
【AWS Summit 2024】オンプレミス上のデータをAWSクラウドの分析基盤に取り込む手法の整理(講演レポート)
2024.06.28
2024年6月20日(木)~ 21日(金)の2日間、幕張メッセにて毎年 延べ 30,000 人が参加する日本最大のAWS を学ぶイベント「AWS Summit Japan 2024」が開催されました。本ブログでは、AWS Summitに実際に参加したエンジニアから、イベントの様子や講演の現地レポートをいち早くお届けします。
今回は、6/20(木) 14:50~15:30に開催されたセッション「オンプレミス上のデータをAWSクラウドの分析基盤に取り込む手法の整理」をリポートします。
AWS Summit Japan 2024 とは?
AWS Summit Japan 2024とは、日本最大の “AWS クラウドを学ぶ”イベントです。基調講演や150を超えるセッション、250を超えるEXPO コンテンツが用意されています。
クラウドコンピューティングコミュニティが一堂に会してアマゾン ウェブ サービス (AWS) に関して学習し、ベストプラクティスの共有や情報交換ができる、全てのクラウドでイノベーションを起こすことに興味がある皆様のためのイベントです。

セッション概要(オンプレミス上のデータをAWSクラウドの分析基盤に取り込む手法の整理)
今回は、6/20(木) 14:50~15:30に開催されたセッション「オンプレミス上のデータをAWSクラウドの分析基盤に取り込む手法の整理」をリポートします。
公式サイト上のセッション紹介は以下の通りです。
“企業にある各種システムからクラウド上の分析基盤(データレイク)にデータを取り込み、クラウドのパフォーマンスを活かして分析する手法は一般的になりつつあります。RDB やファイルサーバー、アプリケーションログ等の多くのデータををクラウド上に効率よく取り込み、活用しやすい形で保存することがデータ活用促進の鍵です。
本セッションでは、オンプレミス上の各種システムからクラウドにデータを取得する際の手法と、取得したデータをどのような形にしてデータレイク上に転送し、保存するか、という「データ取り込み」部分にフォーカスした説明を行います。クラウド環境はAWSを前提にしていますが、他クラウドのオブジェクトストレージへのデータ取り込み方法の一般論としても応用可能です。”
登壇者
当セッションでの登壇者はこちらの方です。
| 会社名 | 登壇者名 | 役職 |
|---|---|---|
| アマゾン ウェブ サービス ジャパン合同会社 | 下佐粉 昭 | サービス & テクノロジー事業統括本部 Data & AI ソリューション本部 プリンシパルアナリティクススペシャリストソリューションアーキテクト |

セッション詳細
様々な方法でのデータ分析の需要が高まっている昨今、AWSのデータ分析基盤が注目されています。しかし、オンプレミスのデータをAWSクラウドに移行するにはいくつかの課題があります。
このセッションでは、こうしたオンプレミス上のデータをAWSに取り込む上で乗り越えるべき課題とその手法について述べられていました。
前提:なぜAWSで分析するのか?
企業の中には、業務システムのデータや工場でのログデータ、Webアプリのデータ、ファイルサーバーのデータなど、様々なデータが存在すると想定できます。こうしたバラバラなデータを統合的に貯蔵・分析する基盤として、AWSなどクラウドの分析基盤は適しています。
また、近頃はデータの分析ニーズは多様化しており、こうしたニーズにオンプレミス上の分析基盤だけで応えるのは学習コスト、構築コスト等の観点から困難であるといえるでしょう。こうした点からも、AWS等のクラウド上の分析基盤でデータを分析することが非常に有効であるともいえます。
移行させる前に考えるべきことは?
移行するといっても、移行元のオンプレミス上の環境次第で適した方法が大きく変わります。そのため、データをクラウドに移行させる前にオンプレミスの環境を把握する必要があります。この把握により、移行における負担を大きく低減させることのできる手法をじっくり検討することができるのです。
このセッションでは、オンプレミスの環境を把握する上で注視すべきポイントとして以下の三点が挙げられていました。
【ポイント1】データ特性の把握 – サイズ
移行元のデータのサイズは、移行における手法の選定や設計で最も大きく影響を与える要素となる。
【ポイント2】データ特性の把握 – 更新方法
更新方法が全体置き換えか、追記のみか、更新・削除があるものなのかによって移行の手法が変わる。
【ポイント3】ネットワーク環境の把握
帯域と利用可能な時間帯を把握し、いかに既存の環境に負担をかけないかを考えることが大切である。
 以下では、それぞれの内容について、セッション内で例示されていたケースを交えながら概観していきます。
以下では、それぞれの内容について、セッション内で例示されていたケースを交えながら概観していきます。
データ取得の方法の例1. Webアプリケーションの行動ログ
ここでは下図のように条件が設定されているとします。

このケースではロガー・ログドライバーにハンドリングを任せ、アプリケーション側にデータレイクへの依存をつくらないことが推奨されていました。
この場合、ログをローカルストレージに出力している場合でもFluentdやAmazon CloudWatch Agentでログを取得し、AWS側へ送信することが可能です。
紹介されていた手法例
データ取得の方法の例2. 工場(IoT)
ここでは下図のように条件が設定されているとします。

このケースではデータ単位が小さいため、バッファリングとリアルタイム性のバランスを検討するとよいとされていました。
また、工場の環境(立地等)によってはネットワークが不安定なことも想定されるため、ネットワークの状態も考慮すべき要件に入れるべきとされていました。
紹介されていた手法例
データ取得の方法の例3. ファイルサーバー
ここでは下図のように条件が設定されているとします。

このケースでは、ファイルサイズが膨大になる可能性を考慮し、新規・更新ファイルのみを検出し、帯域に注意して送信タイミングの調整を行うことが推奨されています。
また、ウィルスやマルウェアへの対応を検討すべきという紹介もされていました。(例:Amazon GuardDutyによるAmazon S3マルウェアプロテクション)
紹介されていた手法例
データ取得の方法の例4. 業務システム
ここでは下図のように条件が設定されているとします。
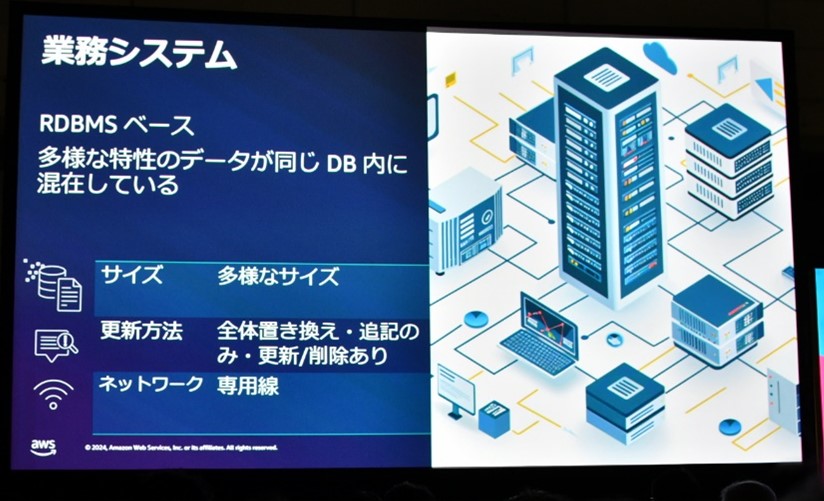
ここでは、業務システムは様々な形態のものがあると想定されており、そのデータの形態別に手法例が紹介されていました。
マスター型の表(全体置き換え)
このタイプは一般的に規模が小さく、データ(表)全体のコピーで問題ないケースが多いとされていました。
紹介されていた手法例
追記のみの表
このタイプでは、インクリメントされる主キーや更新時刻など、追記を判断できる列の有無によって手法が分けられていました。
紹介されていた手法例
更新/削除ありの表
このタイプでは、更新の有無を判断できる列がある場合とない場合によって手法が分けられていました。
紹介されていた手法例
※ CDCがボトルネックを生む可能性や、トラブルが起きた時の対応などを別で検討する必要がある
移行させる前に考えるべきこと まとめ
移行させる前に考えるべきことをまとめると、このようになります。
抽出したデータの蓄積方法
続いて、セッション内でデータを取り込んだ後にどのようにして蓄積するかの手法の紹介も行われていました。手法紹介の前提としてAmazon S3について以下のように説明されています。

続いて、データの更新方法ごとに蓄積手法が整理されていました。
追記のみのデータの蓄積
データ更新が追記のみの場合、以下の二通りの蓄積手法を取ることができます。
| 断面(Snapshot) | 差分のみでなく、更新が入るたびにデータ全体を記録・蓄積する形式です。蓄積していくにつれて断面のサイズが膨大になっていくため、この場合はどこまで古いデータを保存するかを検討する必要があります。 |
| 追記(Append) | 新たに取得した差分データのみを新しいオブジェクトとしてデータレイクに追加する形式です。 |

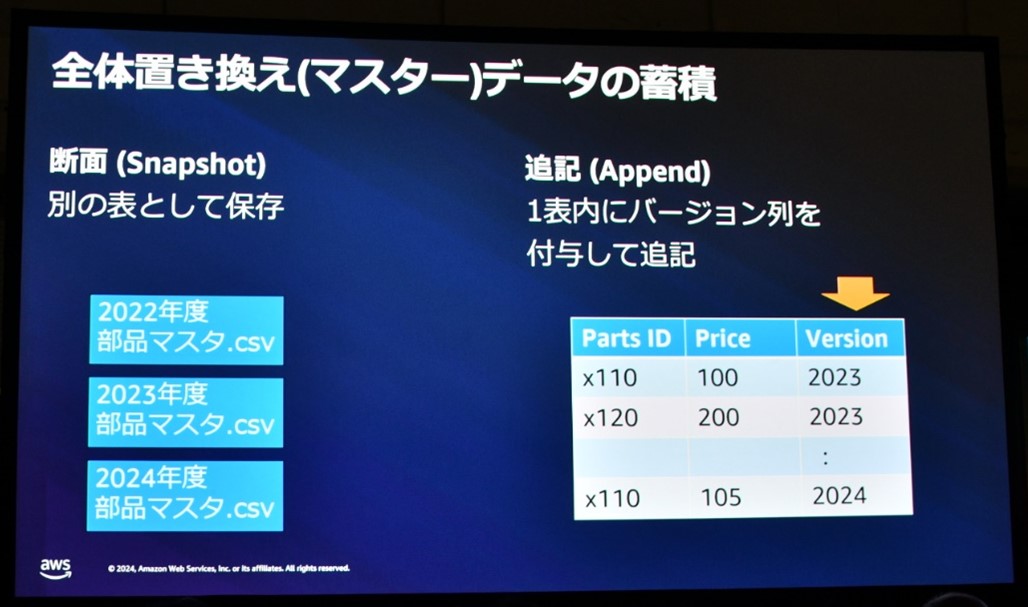
全体置き換え(マスター)データの蓄積
データ更新が全体置き換えである場合、以下の二通りの蓄積手法を取ることができます。
| 断面(Snapshot) | 更新が入るたびに、それぞれの時点でのデータを別の表として保存します。 |
| 追記(Append) | 一つの表の中にバージョン列を付与して追記します。 |
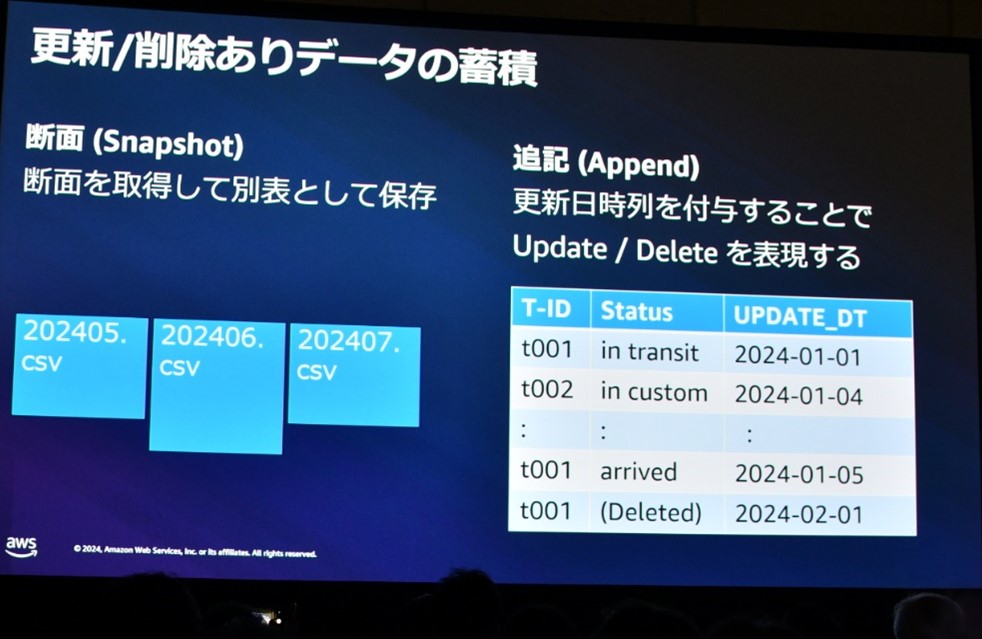
更新/削除ありデータの蓄積
データ更新が更新/削除ありの場合、以下の二通りの蓄積手法を取ることができます。
| 断面(Snapshot) | 更新が入るたびに、それぞれの時点でのデータを別の表として保存します。 |
| 追記(Append) | 更新日時列を付与することで、アップデートと削除を表現します。 |
以上がデータ取得と蓄積についての中心的内容です。
その他の考慮すべき要件
この章では、これまで述べてきた中心的内容に付け加えて考慮すべき諸要件について紹介します。
コンプライアンス上データ削除が必要な際は
令和2年改正個人情報保護法や、EU一般データ保護規則などの法に触れうる場合、以下の対応が求められることがあります。
※この場合、性能とコストがニーズを満たせるかを確認する必要があります。

Open Table Format配置の検討
Open Table Formatをストレージ層(S3)と処理層の間に配置することで効率的にUpdate / Deleteを行えます。その内容は以下のとおりです。
※サポートしているサービス例:Amazon Athena, Amazon EMR, AWS Glue, Amazon Redshift
一方で考慮すべき要件としては以下の点が付け加えられていました。
※完全に削除したいならバージョンを削除する処理が必要

蓄積後のメンテナンスはどうするか
最後に考慮すべき要件はデータ蓄積後のメンテナンスです。理由として、小さいファイルの蓄積によるデータベースの処理性能低下とコストの増大が発生する二つが挙げられています。以下がそれぞれの対応策です。
処理速度低下への対応策
ETL処理でコンパクションを定期実行する
コスト増大への対応策
使用しないファイルはアーカイブする

まとめ
当セッション内容は、以下の4点にまとめられます
「オンプレミス環境のデータを様々な角度から統合的に分析したい」「具体的にクラウドでのデータの取得・蓄積をどうすればいいか分からない」という方は、今回紹介したセッションの内容を参考にされてみてはいかがでしょうか。
また、JIG-SAWからAWSをご契約いただくとAWSの利用料が割引でご利用いただけます。
利用料の割引だけでなく様々な無料特典もつき、システム構築や監視・運用、セキュリティサポートなど各種オプションサービスもご用意しておりますので、お気軽にご相談ください。





