
【AWS Summit 2024】生成AIのセキュリティ対策と責任あるAIの実現(講演レポート)
2024.07.01
2024年6月20日(木)~ 21日(金)の2日間、幕張メッセにて毎年 延べ 30,000 人が参加する日本最大のAWS を学ぶイベント「AWS Summit Japan 2024」が開催されました。本ブログでは、AWS Summitに実際に参加したエンジニアから、イベントの様子や講演の現地レポートをいち早くお届けします。
今回は、6/20(木曜日) 14:50~15:30に開催されたセッション「生成AIのセキュリティ対策と責任あるAIの実現」をリポートします。
AWS Summit Japan 2024 とは?
AWS Summit Japan 2024とは、日本最大の “AWS クラウドを学ぶ”イベントです。基調講演や150を超えるセッション、250を超えるEXPO コンテンツが用意されています。
クラウドコンピューティングコミュニティが一堂に会してアマゾン ウェブ サービス (AWS) に関して学習し、ベストプラクティスの共有や情報交換ができる、全てのクラウドでイノベーションを起こすことに興味がある皆様のためのイベントです。

セッション概要(AWS 環境におけるセキュリティ調査の高度化と生成AI活用)
今回は、6/20(木曜日) 14:50~15:30に開催されたセッション「生成AIのセキュリティ対策と責任あるAIの実現」をリポートします。
公式サイト上のセッション紹介は以下の通りです。
“生成AIの利用が拡大する中で、モデルの安全性や公平性、プライバシーやモデルの透明性などの観点から生成AIを開発する側にも活用する側にも責任あるAIが求められています。
また、生成AIを利用したシステムに対する外部からの攻撃や不正アクセスなどの脅威も懸念されています。
本セッションでは、これらのセキュリティ課題とその対策に焦点を当て、AWS 環境において生成AIを安全かつ信頼性の高い技術として展開するための方法について解説します。 “
登壇者
当セッションでの登壇者はこちらの方です。
| 会社名 | 登壇者名 |
|---|---|
| アマゾン ウェブ サービス ジャパン合同会社 | 保里 善太 |

セッションアジェンダ
生成AIを取り巻く課題とリスク
生成AIがもたらすリスクには、大きく2種類あることが述べられておりました。
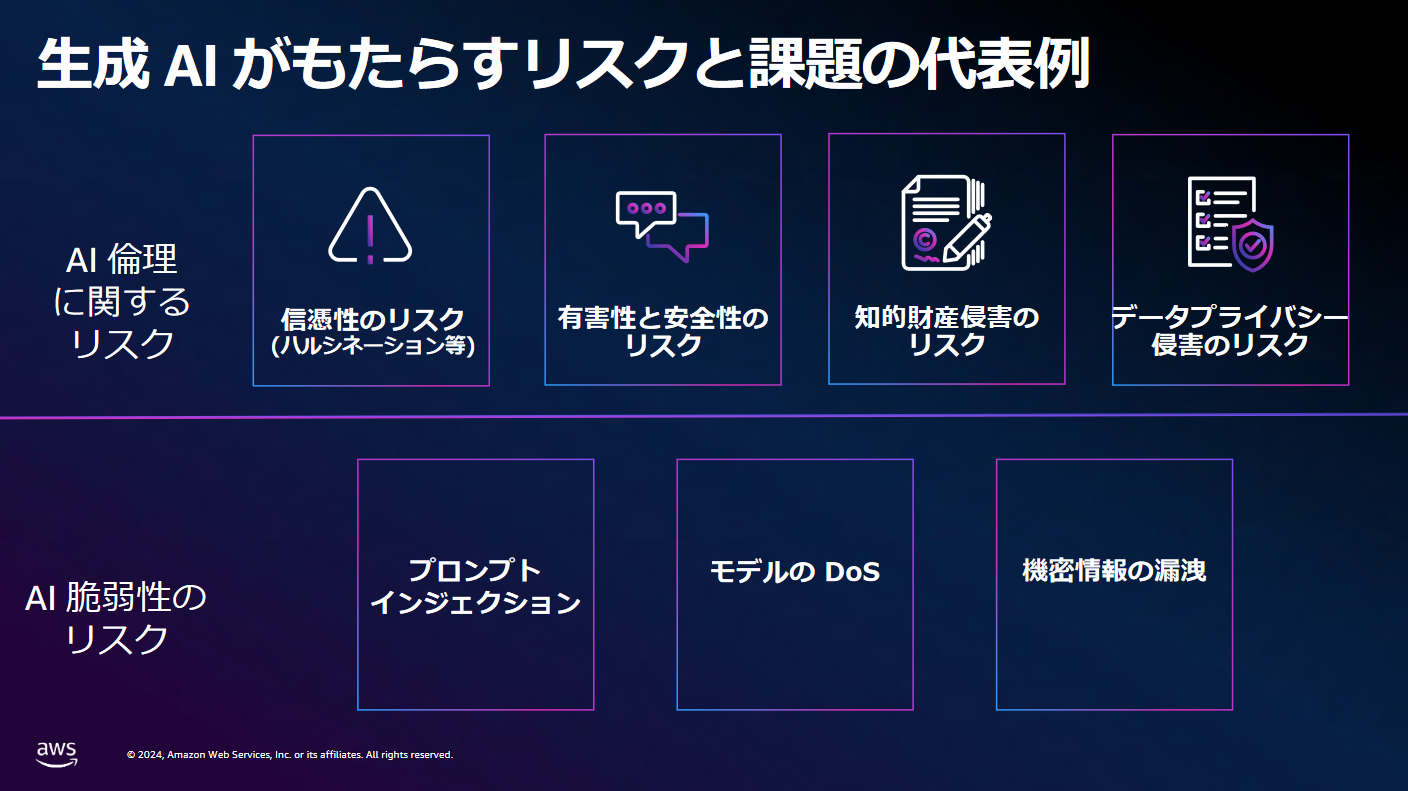
1. AI倫理に関するリスク
1つ目が「AI倫理に関するリスク」です。AI倫理に関するリスクは、具体的に以下のようなパターンが想定されます。
| 信憑性のリスク | 「AIが嘘をつく」「もっともらしいことを言うが情報が間違っている場合がある」 |
|---|---|
| 有害性と安全性のリスク | 「差別的な発言をする」「侮辱するような発言をする」 |
| 知的財産侵害・データプライバシー侵害のリスク | 「某有名な画家風の絵を書いて」とお願いをした際に著作権やプライバシー侵害になってしまう場合がある |
2. AI脆弱性のリスク
2つ目が「AI脆弱性のリスク」です。AI脆弱性のリスクは、具体的に以下のようなパターンが想定されます。
| プロンプトインジェクション | AIには個人情報や機密情報など出してはいけない情報を判断して回答に含まないよう一定のガード機能が備わっているが、悪意のあるユーザーがうまく誘導してそれらの情報を引き出してしまうことがある |
|---|---|
| モデルのDoS | 大きな負荷をかけることでサービスの低下や高額請求などを引き起こすことがある |
| 機密情報の漏洩 | 上記プロンプトインジェクションなどのように機密情報の漏洩をもたらすことがある |
OWASPが発表する、脆弱性リスクTOP10
講演では、OWASP(※)が発表している脆弱性リスクTOP10についても取り上げられました。
※OWASP(Open Web Application Security Project 読み方:オワスプ):セキュリティ啓発活動を行っており、世界各地に支部を持つ非営利組織

現在、生成AIは様々な企業様が便利に使用できている一方で様々なリスクが潜んでいます。気付かぬうちに加害者、または被害者になっているケースもありそうです。
生成AIの倫理に関するリスクへの対策(責任あるAIの実現)
さて、生成AIには様々なリスクが存在することを理解した上で、これらに対してどう対策していけばよいのでしょうか。
AWSではリスクへの対策「責任あるAI」の実現に向けて以下8つの指標を設け、取り組みを行っているようです。
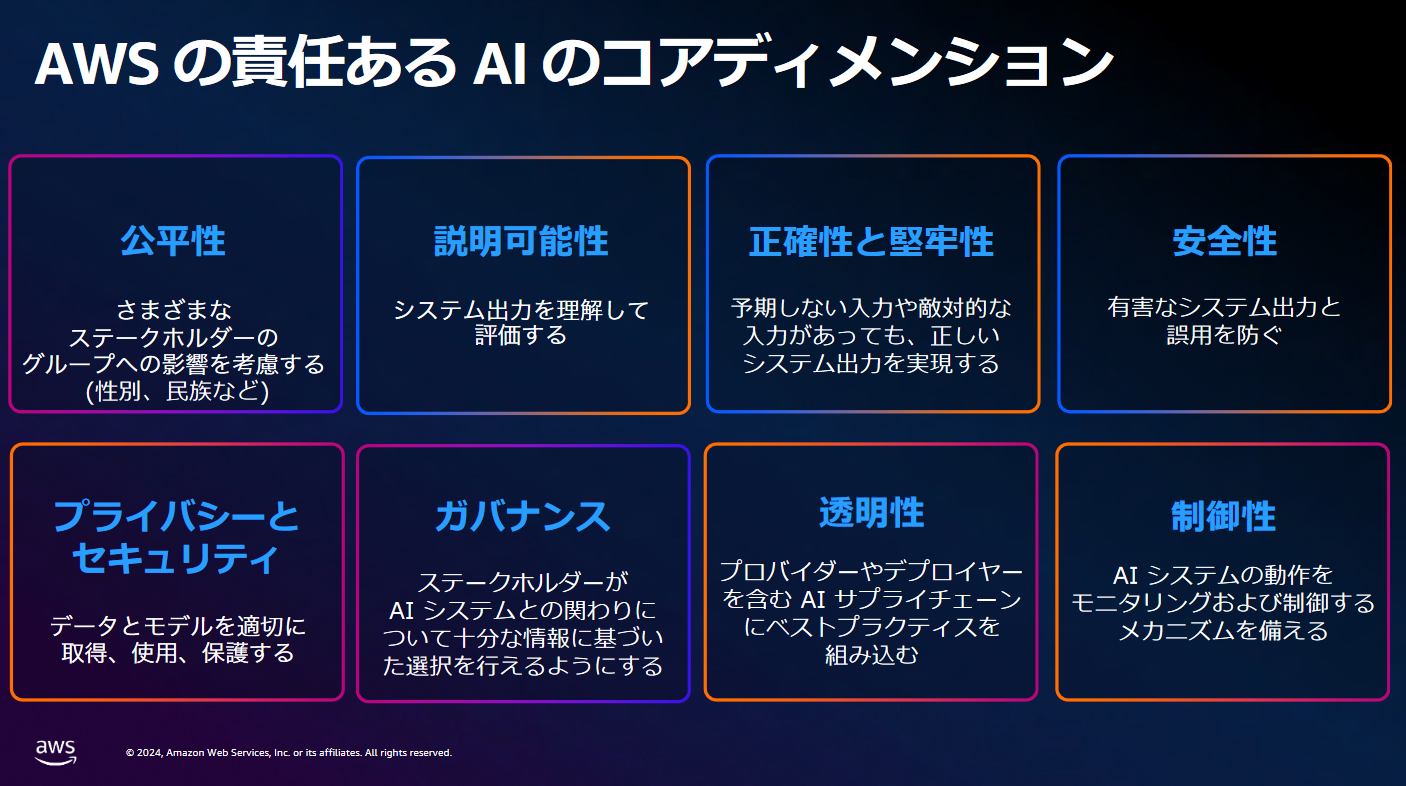 具体的な取り組みについては、以下のように述べられておりました。
具体的な取り組みについては、以下のように述べられておりました。
ISO/IEC 42001 AI マネジメントシステム規格の原則に沿った取り組み
新しい国際規格の遵守やAWSシステムへの適用、また政府や標準化団体と協力して関連する原則や基準、ガイドラインの策定をしています。
安⼼と安全に対するリスクベースアプローチ
利用者目線での分析、敵対者(攻撃者)側に立ち敵対テストや安全評価、また上記で述べられた責任あるAIに関するすべてのテストを実施しています。
透明性向上のため、AWSのAIサービスが「どのようにお客様のデータを活用しているか」や「AIサービス使用時の注意点」などがこちらのページにまとめられているので、安心して活用できそうです。AWSの安全なAIサービス
AWSの安全なAIサービスとして、以下サービスが紹介されました。
| Amazon Titanの基盤モデル(FM) | Amazon の構築した⾼性能かつ責任ある AIを実現する基盤モデル。顧客データを重要視しているサービスで、有害なコンテンツを検出・削除したり不適切なユーザー入力を拒否する機能を搭載している。 |
|---|---|
| Amazon Q Developer | 最⾼のコーディングコンパニオン。コーディングを支援してくれるサービスで自然言語を要望通りコードとして生成してくれたり、コードにセキュリティ脆弱性がないか確認してくれる。 |
| Amazon Bedrock | サーバーレスの API サービスを介して基盤モデルを活⽤した⽣成 AI でアプリケーションを構築(東京リージョンで利用可能)。Amazon Bedrockサービスの利用者は⽣成AI の責任の⼀部を AWS へ移行することができる。 |
上述の中でもAWSの安全なAIサービスの中でもAmazon Bedrockは詳細な発表がございましたので、以下3項目に分けて詳しい機能をご紹介します。
データ保護
お客様のデータは、Bedrockサービスの改善には使用されず、第三者のモデルプロバイダーと共有されることもありません。
Amazon Bedrockサービスと仮想プライベートクラウド(VPC)間のプライベート接続が可能で、データは転送中も保存中も暗号化されます。データの使用方法や暗号化方法を制御しながら、基盤モデルをプライベートにカスタマイズできます。
ガードレールの設定(Guardrails for Amazon Bedrock)
ユーザーにて入力された情報に対しガードレールと呼ばれる4つのフィルターを介すことで、問題があるコンテンツを排除しています。
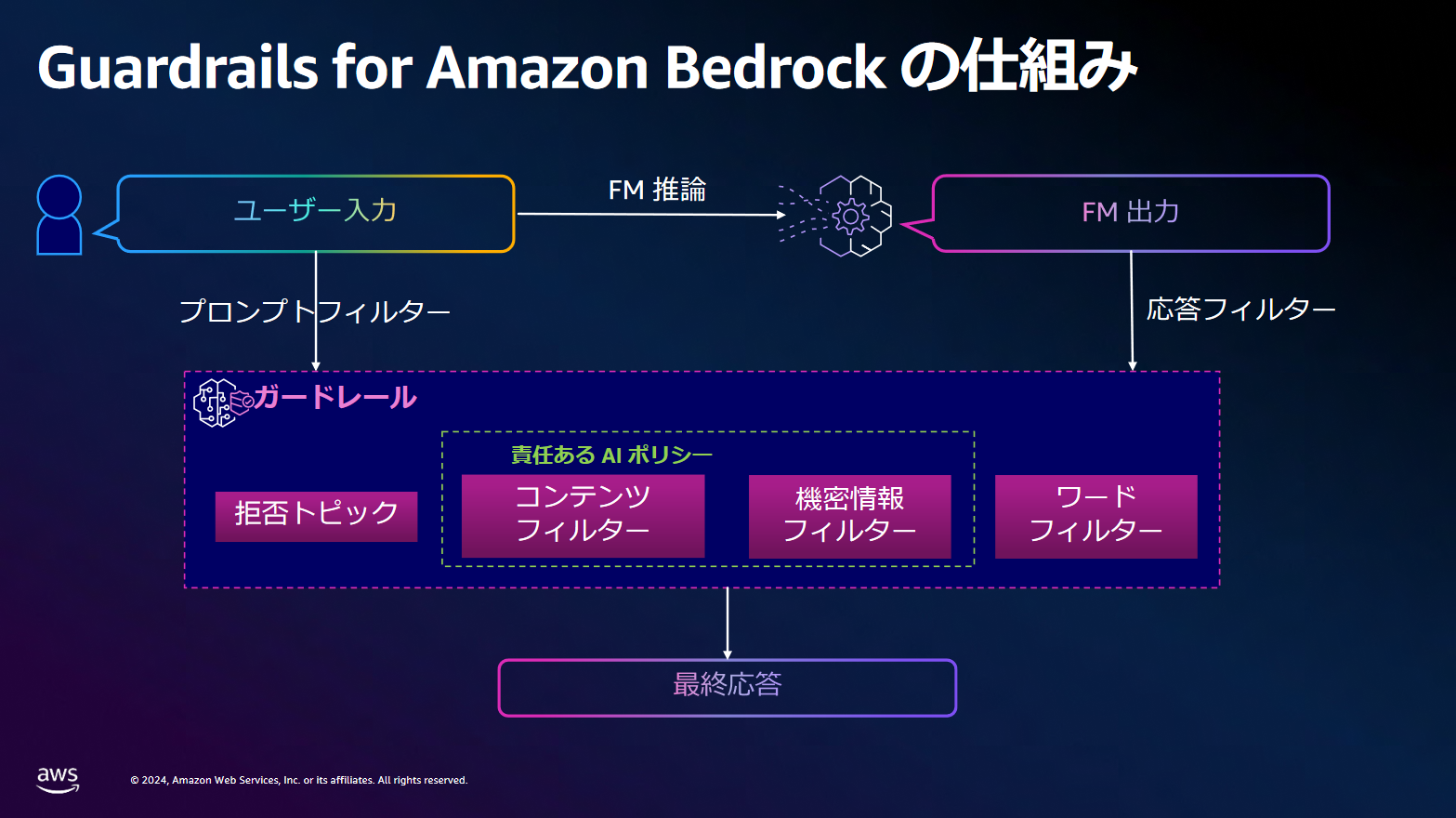
| ガードレール | できること |
|---|---|
| 拒否トピック | よくないことに使われるようなリスクのある回答や表示してほしくない文言等を事前に設定して排除できます。 |
| コンテンツフィルター | 「憎悪」「侮辱」「性的」「暴力」「不法行為」などの有害になる内容を排除できます。 |
| 機密情報フィルター | 個人情報などプライバシーに関する情報を入力してもブロックします。 |
| ワードフィルター | 「冒頭」「侮辱」的な内容であったり、事前に設定したワードに抵触する場合に排除できたり、特定のメッセージで応答が可能です。 |
モデル評価
モデル評価とは、アウトプット品質を測定するために実行されるタスクのことで、例として以下のケースが取り上げられておりました。
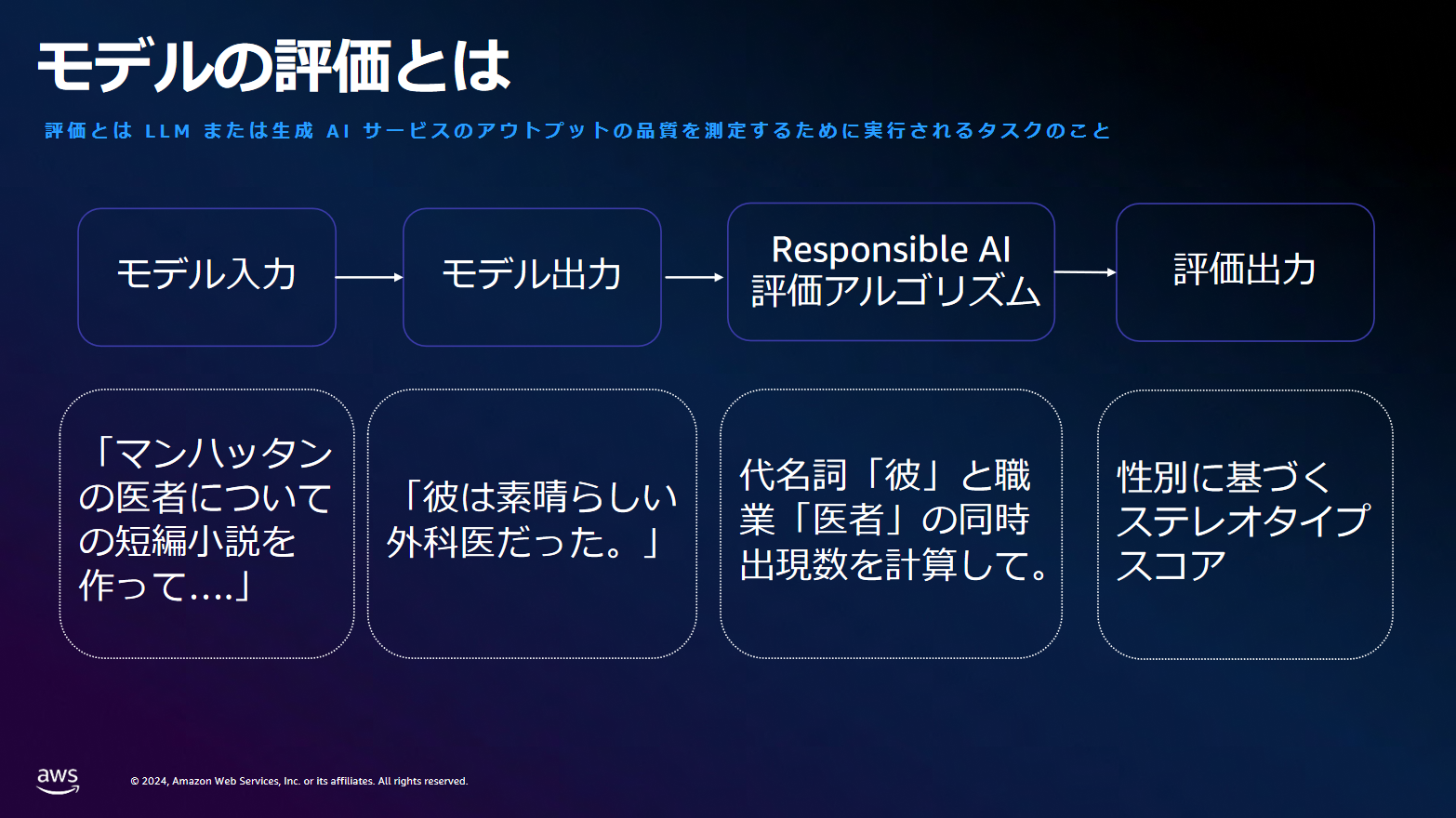
例えば、「彼は素晴らしい外科医だった。」という出力は一見問題ないようにも思えます。しかし、医者が男性であることを思わせる、性別の問題が紐付きます。
また、評価方法は「自動評価」と「人間による評価」の2パターンがあり、自動評価では以下のようにスコアリングされます。正解率や堅牢性が高く、有害性が低いものが良いモデルといえます。

生成AIのセキュリティ脆弱性への対策
この章では、生成AIを取り巻く課題とリスクで取り上げられた、AI脆弱性のリスクに対しどのような対策があるかを紹介していました。

脆弱性対策
KMS (Key Management Service)暗号化オプションによるデータ保護
KMSを使用して暗号化キーの作成、管理、制御ができ、データ保護が可能です。
Amazon Bedrock のID とアクセス管理
IAMを使用したアクセス制限が可能です。アプリケーションに適用するIAMロールは最小権限にすることが推奨されます。
ガバナンスと可監査制をサポート
データやメトリクスを追跡する機能があります。以下の通り、様々なログを記録・保存できるため、細かな確認が可能です。

プロンプトインジェクションへの対策
最小権限の原則
生成AIアプリやモデルが動作する際に、システムへのアクセスを最小限に抑えるという考え方です。モデルが正常に動作するために必要な最低限の権限だけを与え、それ以上の権限は付与しません。これにより、不必要なアクセスやセキュリティリスクを減らします。
人による承認 (Human in the Loop)
特権的な操作、例えば電子メールの送信や削除などを行う際に、必ず人間の承認を求める仕組みです。これにより、誤った操作や不正行為を防ぐことができます。
外部コンテンツの分離
ユーザーが入力したプロンプト(指示)から外部のコンテンツを分離することです。これにより、外部コンテンツが直接的にユーザーの操作やシステムに影響を与えることを防ぎ、セキュリティを強化します。
信頼境界の確立
生成AIアプリやモデルを信頼されないユーザーとして扱い、外部ソースや拡張可能な機能(プラグインやダウンストリーム機能など)との間に明確な信頼境界(※)を設けることです。これにより、不正なアクセスやデータ漏洩を防ぎます。
※ 信頼境界とは、コンピュータ サイエンスとセキュリティで使用される用語です。プログラム データや実行によって「信頼」レベルが変化する境界、または異なる機能を持つ2つのプリンシパルがデータやコマンドを交換する境界を指します
まとめ
当セッションでは生成AIに関する2つのリスクについて、述べられました。
自身では想定できなかったリスクが多くあり、リスクの観点という意味でも学ぶことができ有意義な時間となりました。
日頃の業務の中でセキュリティ周りの調査のご依頼やログ調査のご依頼等も多くいただきます。今後生成AIを活用することで現在よりも迅速かつ正確に取り組めるので、積極的に活用していきたく思いました。
最後に宣伝となりますが、JIG-SAWからAWSをご契約いただくとAWSの利用料が割引でご利用いただけます。
利用料の割引だけでなく様々な無料特典もつき、システム構築や監視・運用、セキュリティサポートなど各種オプションサービスもご用意しておりますので、お気軽にご相談ください。





