
【AWS Summit 2024】AWS で実現する生成 AI データ分析基盤構築のベストプラクティス(講演レポート)
2024.07.04
2024年6月20日(木)~ 21日(金)の2日間、幕張メッセにて毎年 延べ 30,000 人が参加する日本最大のAWS を学ぶイベント「AWS Summit Japan 2024」が開催されました。本ブログでは、AWS Summitに実際に参加したエンジニアから、イベントの様子や講演の現地レポートをいち早くお届けします。
今回は、6/21(金曜日) 12:50~13:30に開催されたセッション「AWS で実現する生成 AI データ分析基盤構築のベストプラクティス」をリポートします。
AWS Summit Japan 2024 とは?
AWS Summit Japan 2024とは、日本最大の “AWS クラウドを学ぶ”イベントです。基調講演や150を超えるセッション、250を超えるEXPO コンテンツが用意されています。
クラウドコンピューティングコミュニティが一堂に会してアマゾン ウェブ サービス (AWS) に関して学習し、ベストプラクティスの共有や情報交換ができる、全てのクラウドでイノベーションを起こすことに興味がある皆様のためのイベントです。

セッション概要(AWS で実現する生成 AI データ分析基盤構築のベストプラクティス)
今回は、6/21(金曜日) 12:50~13:30に開催されたセッション「AWS で実現する生成 AI データ分析基盤構築のベストプラクティス」をリポートします。
公式サイト上のセッション紹介は以下の通りです。
“今日では、新しいデータアーキテクチャパターンの急速な広がりと、生成 AI などの革新的な技術のブレイクスルーにより、データ分析がクラウドに急速に移行しています。
まさに今、クラウドでデータを有効活用する絶好の機会といえます。企業や組織はコスト効率を維持しながらパフォーマンス最大化を目指し、データ分析や生成 AI アプリケーションのためのデータ基盤を構築する上で、データ戦略とデータパイプライン最適化に関するベストプラクティスを必要としています。
本セッションでは、AWSの主要な分析サービスにおけるベストプラクティスについて学び、データから迅速かつ高いコスト効率で結果を得る方法をご紹介します。 “
登壇者
| 会社名 | 登壇者 |
|---|---|
| アマゾン ウェブ サービス ジャパン合同会社 |
田中 智大 シニアクラウドサポートエンジニア、AWSサポートエンジニアリング |
セッション詳細
本セッションでは、生成AIを活用するにあたってデータの取り扱いのベストプラクティスを下記3セクションに分けて紹介されておりました。
生成AIのしくみ
生成AIとは、様々なコンテンツやアイデアを生成するために、大規模データセットで事前学習を行った大規模モデルを使用する技術です。
基本的な流れとしては、下図のようにユーザーが生成AIアプリに質問を入力し、その質問がアプリを通じてLLM(大規模言語モデル)へのプロンプトとして渡されます。
その後、LLMによって推論された結果がアプリに返され、ユーザーに表示されます。
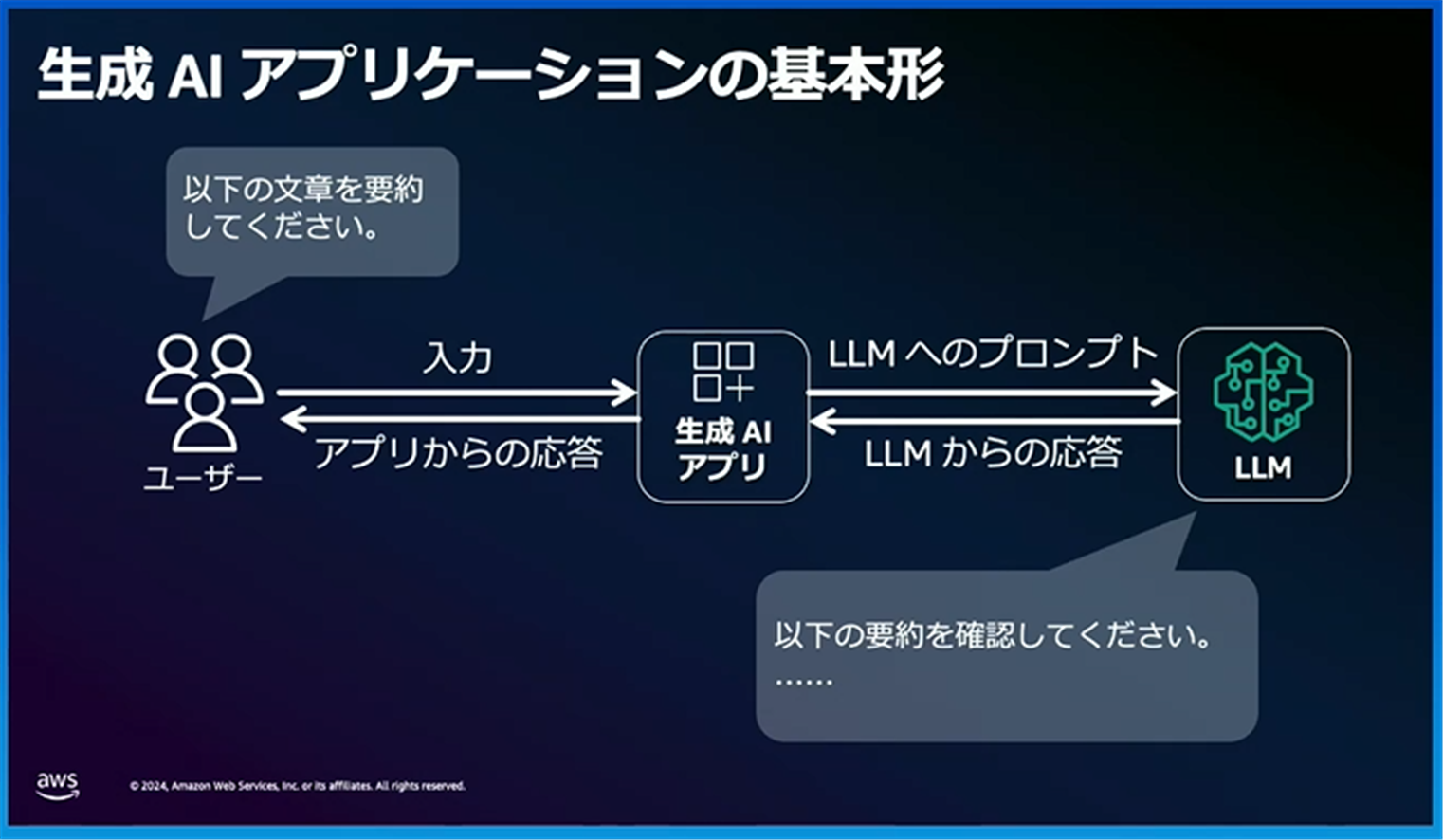
生成AIの問題点
LLMによって推論された結果がアプリに返され、ユーザーに表示される際、AIモデルがユーザーの質問に対する正確な回答を持ち合わせていない場合があります。
その場合、一般的かつそれらしい回答を返すことがありますが、これはユーザーの要件に沿っていない誤った回答や曖昧な回答、古い知識に基づく回答につながる可能性があります。
本セッションでは、これらの課題を解決するためのソリューションが紹介されています。
時間・コストをかけずに学習できる「文脈内学習」と「RAG(検索拡張生成)」
AIモデルが持たない知識や古い知識の問題を解決するには、知識の追加や更新が必要です。具体的なモデルのカスタマイズ方法として、学習時間やコストをかけずにトレーニングできる「文脈内学習(In-Context Learning)」が注目されています。
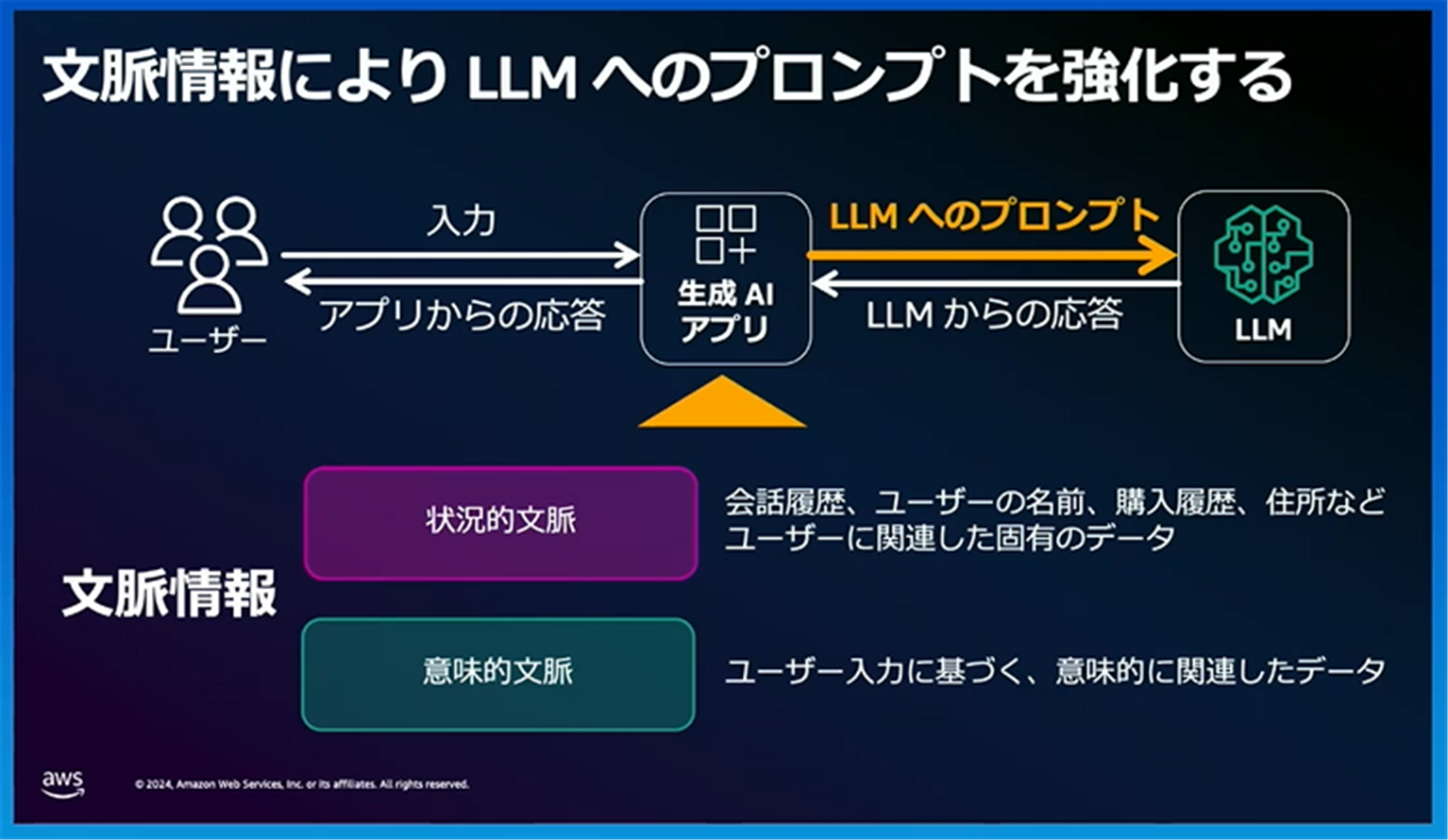
文脈内学習では、モデルに存在しない知識に対応するために、RAG(Retrieval Augmented Generation:検索拡張生成)と呼ばれるアプローチが用いられています。
このアプローチでは、ユーザーの入力に基づいて外部データから関連情報を収集し、AIモデルへの入力を強化します。
RAGアプローチを用いて、「状況的文脈(会話履歴、ユーザー名などユーザーに関連する固有データ)」と「意味的文脈(ユーザー入力に基づく意味的に関連したデータ)」を生成AIアプリケーションに提供することで、これらの情報がAIモデルへの入力として追加され、文脈情報を考慮した回答が生成されます。
生成AIアプリのためデータ分析基盤アーキテクチャ図が以下の通りとなっております。
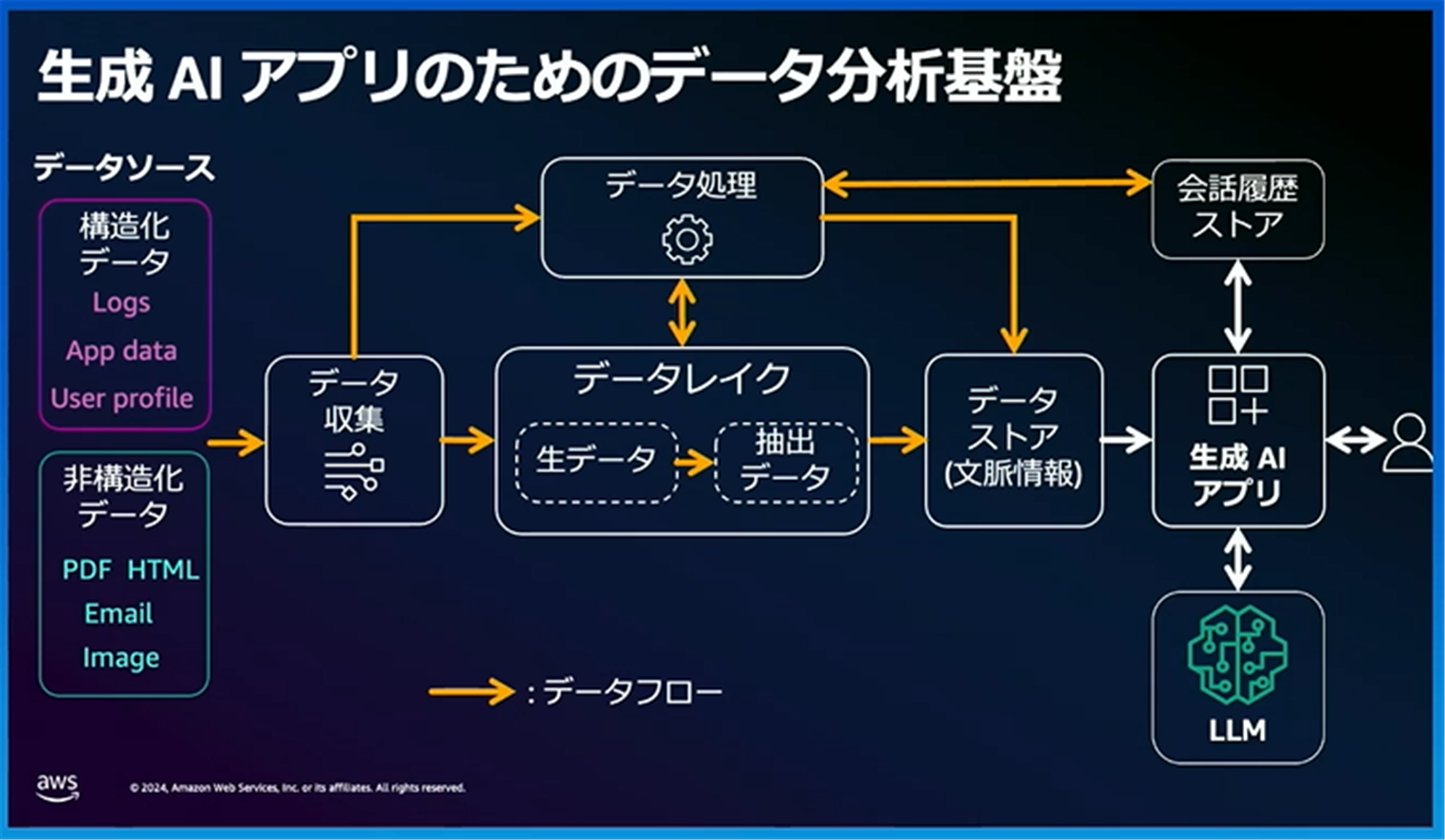
データソースから構造化データと非構造化データを収集し、必要に応じてデータ処理を行うことやデータレイクへ生データとして保存します。 データレイクへ保存した生データから文脈情報を抽出し、データストアへ保存します。
このアーキテクチャ図は、データストアを境に、左レイヤーが「データ分析基盤」、右レイヤーが「生成AI アプリケーション」で構成されています。AWSサービスを割り当てると、以下のように構成することができます。
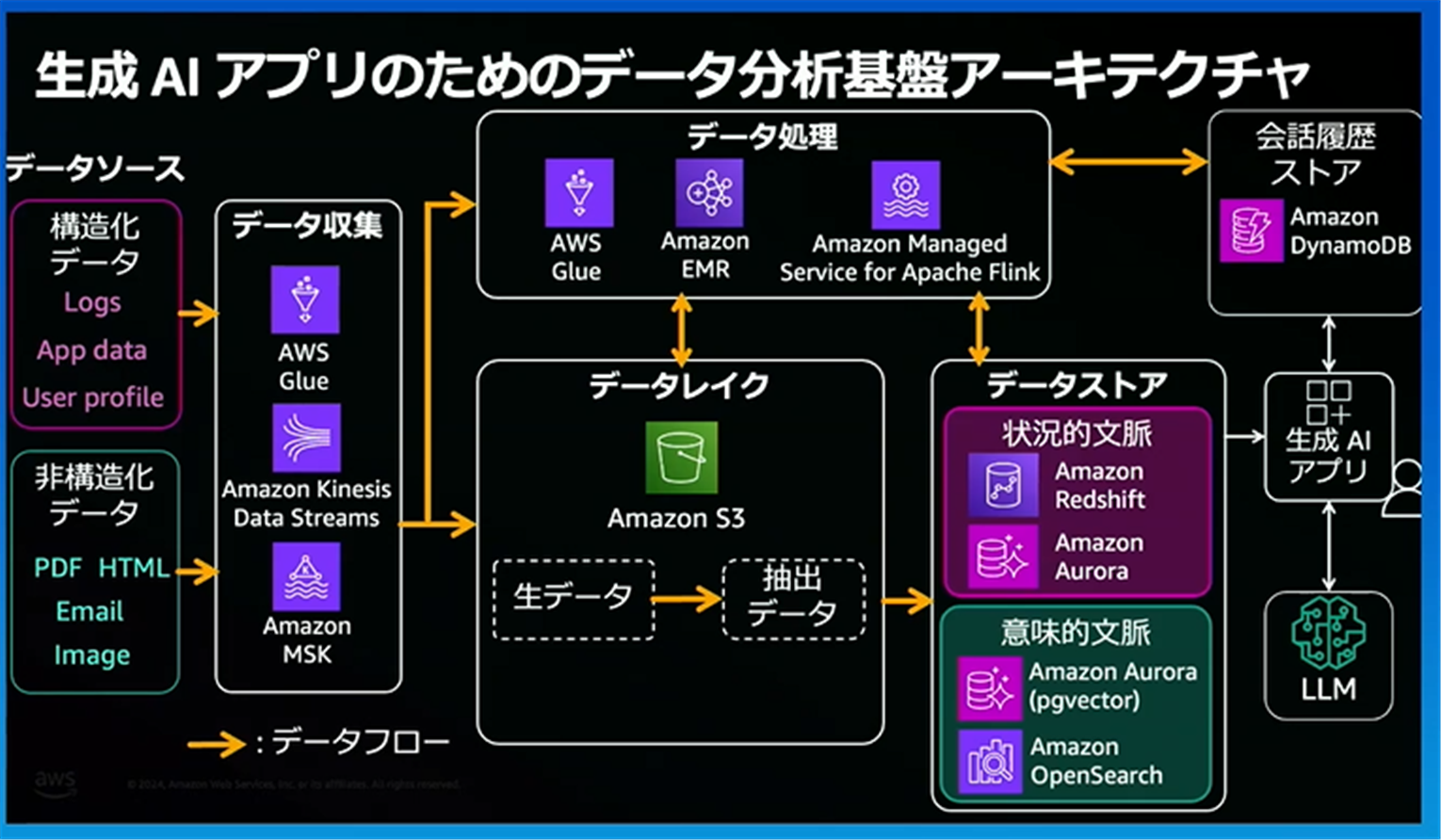
まとめ
従来の課題であったLLMの知識範囲をRAGアプローチを用いることで拡張し、文脈情報を生成AIアプリケーションに与えることで、より価値の高い情報をユーザーに提供することができます。
これらのデータ分析基盤は、すべてAWSサービスを組み合わせることによって一元管理することが可能です。
最後に宣伝となりますが、JIG-SAWからAWSをご契約いただくとAWSの利用料が割引でご利用いただけます。
利用料の割引だけでなく様々な無料特典もつき、システム構築や監視・運用、セキュリティサポートなど各種オプションサービスもご用意しておりますので、お気軽にご相談ください。






