
RDBMSのパフォーマンス低下を改善
DB高速化を実現する方法とは?
2021.08.05
今回は、Relational Database Management System(以下、RDBMS)で数千万レコードを管理する方法をご紹介します。
大量のレコードを持ったRDBMSのパフォーマンス向上にお悩みの方や、パーティショニングのコツを知りたい方におすすめです。
RDBMS、レコード増加によって生じる問題とは
開発者がアプリケーションを開発する際に、RDBMSを選択する理由は多くあります。
それは、複雑なデータを管理できたり、時系列でデータを保存したりできる点です。 そういったアプリケーションを開発する上で欠かすことのできない機能が、多くの実績と共に提供されています。
一方で、レコード数の増加によるパフォーマンスの低下に悩む方も多いのではないでしょうか。 なぜならば、レコードの増加量については、予想が可能なものとそうでないものがあるからです。
例えば、ユーザーの特定の履歴データを保存したケースを想定します。
レコード量が増加した場合、その増加分はレコメンド用として後付けされたものかもしれません。後々の広告メール配信など、比較的時間に余裕を持てるバッチ処理であればすぐに問題が出現する可能性は低いでしょう。
しかしながら、徐々にデータの取得や更新速度、またその後に続くシステムに影響が出始め、最終的には改善のために対策をする必要が出てきます。
そこで今回は、どのタイミングでもRDBMSのパフォーマンス向上への効果が期待できる、パーティショニングの方法についてご紹介します。
この後に続く検証のセクションでは、大量のレコードを想定した新規テーブルの作成を行い、パフォーマンスの検証を行っています。既存のデータがRDBMSにある場合は、データ移行による影響を考慮した上で作業を行ってください。

パーティショニングを行うメリットと検証概要
まず、パーティショニングの概要についてお伝えします。
パーティショニングとは、データベースにおけるテーブル内のデータを分割して保持する機能です。
分割をしてもアプリケーション側からは一つのテーブルとして扱うことができるため、特にデータ量が多くなったRDBMSのパフォーマンス向上に大きく期待ができる場合があります。パーティショニングについては多くの参考サイトがあるため、より詳しく知りたい方は、お調べいただくとより理解が深まると思います。
今回の検証では、PostgreSQL(バージョン9.6)のDockerイメージとPython3.7を利用し、パーティショニングしたものと、していないもの2つのクエリコストを比較し、結果をお伝えいたします。
今回、検証に利用した環境は以下です。
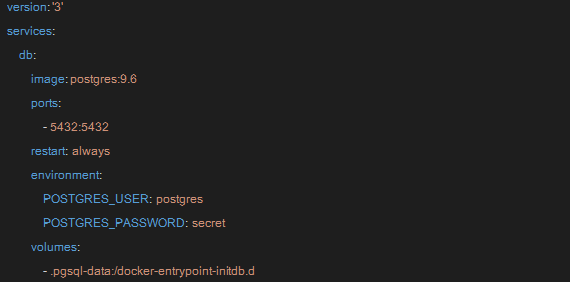
・docker-compose.yaml
・requirements.txt
なぜパーティショニング検証を行うのか
実践に入る前に、「なぜ本検証を行うのか」について簡単にお伝えします。
一番の理由は、リスク検証や比較、パフォーマンスチェックをより身近なものに感じいただきたいと思ったためです。そのために、多くの方が利用するDockerやPythonを用いて、ローカル環境での環境構築~パーティションの作成、クエリコストの表示まで一連の検証方法をご紹介します。
検証する手段は、Not Only SQL(以下、NoSQL)やインデックス作成、またサーバーのスペックを上げるなど様々です。
その際に、候補の一つとして是非パーティショニングをご検討いただければと思います。
またこの技術は、弊社の様々なサービスの裏側を支えています。
検証から分かったパーティショニングの効果とは
検証環境の構築
1.今回のプロジェクトのディレクトリを作成します。
2.次に「検証の概要」で記載した docker-compose.yaml をもとにPostgresコンテナを立ち上げます。
3.次に同ディレクトリにPythonの実行環境を作成します。
4.作成後は仮想環境に入り、必要なライブラリ(「検証の概要」で記載したrequirements.txt)をインストールしてください。
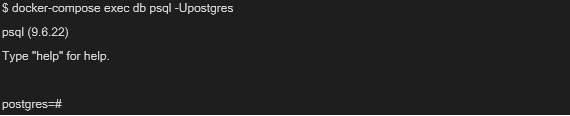
5.これで準備は完了です。Postgresコンテナへは下記のコマンドで入ることができます。
検証
1.Postgresコンテナに入り、まずは親となるテーブルを作成します。
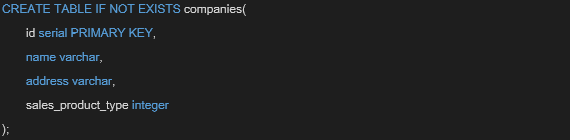
作成に成功すると、ターミナル上で「CREATE TABLE」の文字を確認できます。パフォーマンス比較のためにパーティショニングなしのテーブルを検証する場合、次の2.へは進まずに5.のサンプルデータ作成の手順へ移り、検証を行ってください。
2.次に子テーブルを作成します。
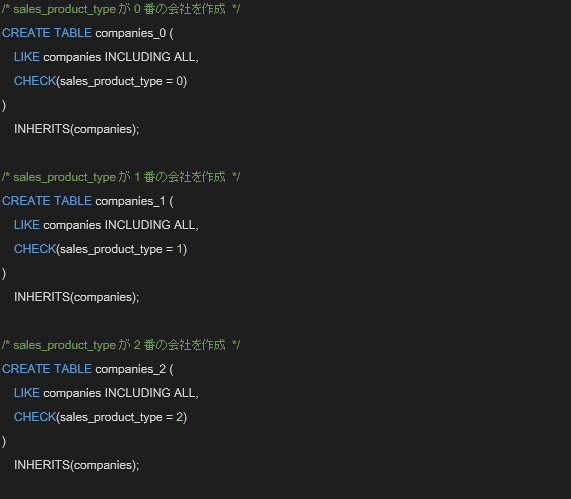
今回の検証ではsales_product_type毎に子テーブルを作成することにします。弊社の場合、子テーブル作成の目安として会社名や住所程度の少ない情報を持ったレコードが100万件単位で区切れるよう、パーティションキーの検討を行っています。
作成が成功すると、親のテーブルを継承して作成された子テーブルの情報と「CREATE TABLE」のメッセージを確認する事ができます。
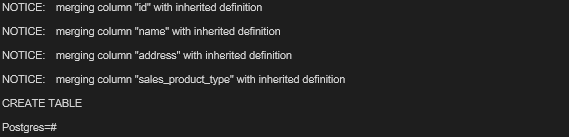
3.次に、トリガー関数を定義します。
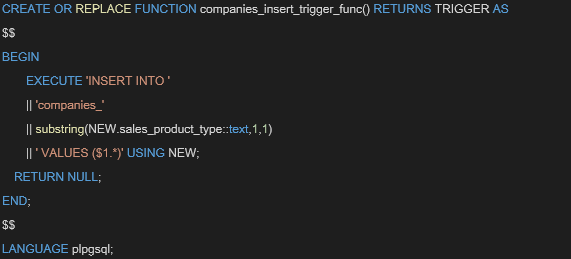
トリガー関数の定義が成功すると、「CREATE FUNCTION」のメッセージを確認する事ができます。INSERT文を最小に抑えるため、テーブル名を動的に変更するよう設定している部分がポイントです。(※今回は検証用としてsales_product_typeをプレフィックスとし、1桁のみである想定)
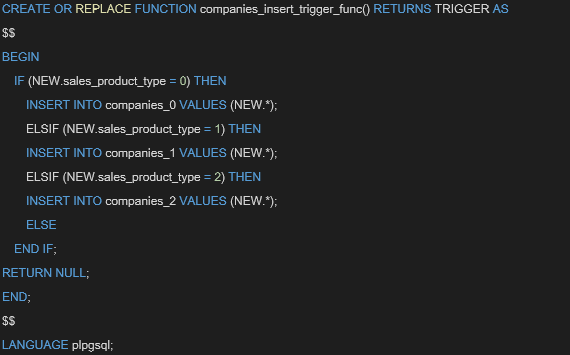
パーティショニングを紹介しているブログでは、IFELSEの条件分岐によるINSERT文が多く紹介されています。
参考までにIFELSE文の場合、下記のような冗長なコードになってしまいます。
4.次に、3.で作成したトリガー関数を親テーブルに対して定義します。

トリガー関数の定義が成功すると、「CREATE TRIGGER」のメッセージを確認する事ができます。
これでパーティショニングは完了です。
5.最後に、作成したテーブルにサンプルデータを流し込みます。
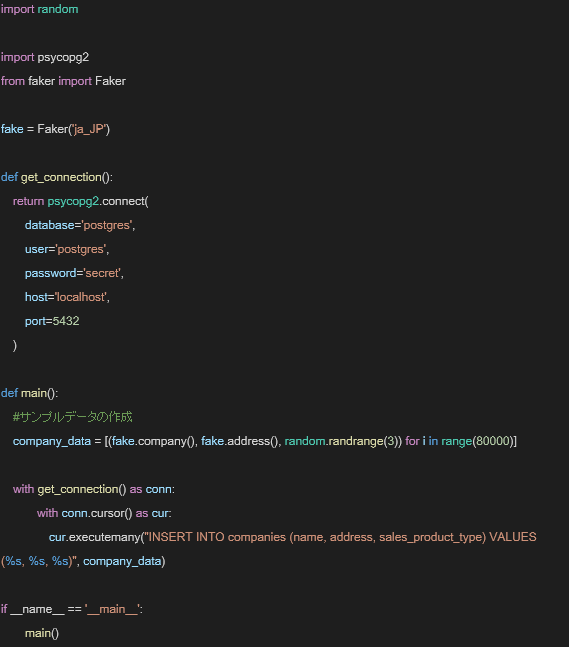
上記のpythonファイルを実行する事で、8万件のサンプルデータが作成されます。
6.それでは実際にパフォーマンスを比較してみましょう。比較に利用するSQLは下記です。
まずは、パーティションニングを行っていないテーブルのパフォーマンスチェックを行います。結果は以下となりました。

一方、パーティショニングしたテーブルの結果は以下のようになりました。
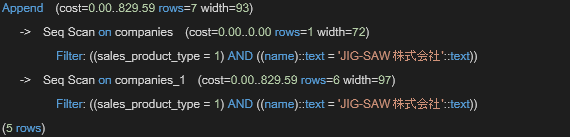
sales_product_type=1のデータが入った子テーブルcompanies_1に対してのみスキャンが行われ、クエリコストが減っていることが分かります。
検証結果
パーティショニングしたテーブルと、していないものを比較すると、コストにおいては約3倍の差が発生しています。
・パーティションあり
・パーティションなし
終わりに
データの保存先としてRDBMSを選択する理由はどれも重要なものばかりです。
しかしながら、データ量とパフォーマンスは反比例しており、大規模なデータを管理するにあたっては、様々な検証が必要となります。今回は、パフォーマンス向上手段の候補として挙げられるパーティショニングについての検証方法と要点をご紹介しました。
8万件程度のサンプルですが、実際にパフォーマンスには差があり、パーティショニングの効果があることが明らかになりました。
RDBMSのパフォーマンス向上にお悩みの方は、是非一度パーティショニングを試してみてはいかがでしょうか。




