
【AWS re:Invent2022】実践!AWS DeepRacer!
2022.12.02
AWSが主催するクラウドコンピューティング最大のイベント「AWS re:Invent」が、2022年11月28日~12月2日にかけてアメリカのラスベガスにて開催されます。本ブログでは、AWS re:Inventに実際に参加したエンジニアから、イベントの様子やKeynote(基調講演)の現地レポートをいち早くお届けします。
今回は、11/30(水)11:30~13:30に開催されたAWS DeepRacerに関する講演をお伝えします。
AWS re:Invent とは?
re:Inventとは、Amazon Web Services(以下、AWS)が主催するAWSに関するセッションや展示ブース、試験準備のためのブートキャンプやゲーム化された演習などを通じて、参加者が主体的に学習できるAWS最大のイベントです。
昨年も今年同様でラスベガスとオンラインにて開催されており、85以上の新サービスや新機能が発表されました。昨年の参加人数はオンサイト参加者2万人以上、バーチャル参加者は60万人以上になります。
AWS DeepRacer: 機械学習を実践する
今回は、11/30(水)11:30~13:30に開催されたAWS DeepRacerに関する講演についてリポートします。
公式サイトによるセッション紹介を日本語訳すると、以下のような内容になります。
“開発者の皆さん、エンジンを始動してください! AWS DeepRacer は、文字通り、機械学習 (ML) を使用する最速の方法です。
このワークショップは、あらゆるスキルレベルの開発者に、高度な ML テクニックである強化学習の基礎を学ぶために AWS DeepRacer を実践する機会を提供します。
このワークショップでは、AWS DeepRacer コンソールに飛び込んで、90 分以内にレースの準備が整った自動運転アプリケーションの強化学習モデルを構築します。モデルを教室から re:Invent の AWS DeepRacer Arena に持ち込み、賞品と栄光を競います。”
登壇者
登壇者はこちらの方です。
| 会社名 | 登壇者 | 役職 |
|---|---|---|
| Amazon Web Services | Tim O’Brien | Principal Solution Architect |
セッション会場の様子

今回のセッションの形式はWorkShopでした。
WorkShopセッションは実際に手を動かしてAWSサービスを使って何かを作るハンズオン形式のセッションです。筆者は英語があまり得意ではないですがハンズオン資料が公開されていたためそちらを翻訳することで問題なく実施できました。
セッション概要
セッションのアジェンダは以下の通りです。
前半ではAWS DeepRacerの概要説明や強化学習の紹介があり後半では実際にAWS DeepRacerコンソールを使用したハンズオンワークショップが行われました。
本記事ではAWS DeepRacerの概要と実際にどのようにハンズオン実施したかを記載していきたいと思います。
AWS DeepRacerとは
AWS DeepRacerは機械学習を使用して自律走行を行うミニカーです。
エンジンに使用する機械学習モデルはAWSコンソール上から作成することができ仮想空間上のレースコースでのテストを行うこともできます。
AWS DeepRacer実践
ここからは実際にAWS DeepRacerのエンジンをコンソール上から作成する方法をお伝えしたいと思います。
AWS DeepRacerサービスにログイン
まずはAWSコンソール上からAWS DeepRacerコンソールにアクセスします。DeepRacerは2022年現在バージニア北部リージョンのみ使用可能となっています。
モデルの作成
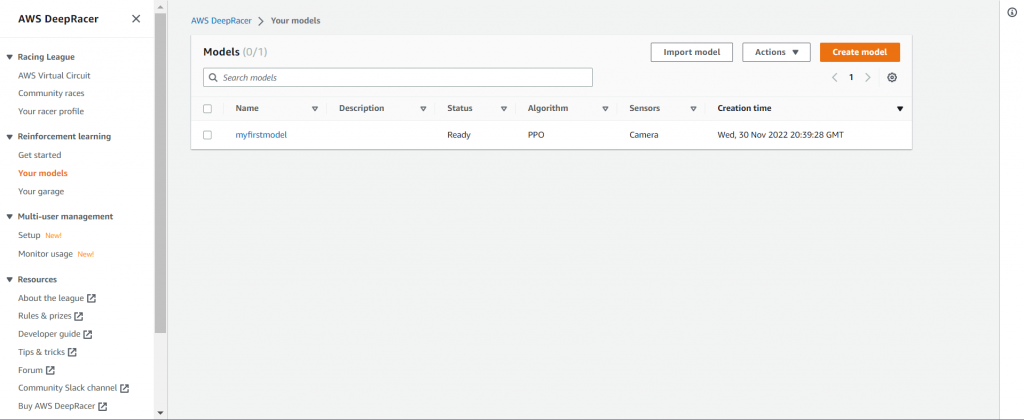
ナビゲーションペインからyour model、crate modelの順に選択しモデルの作成を行っていきます。
モデル名と環境の選択
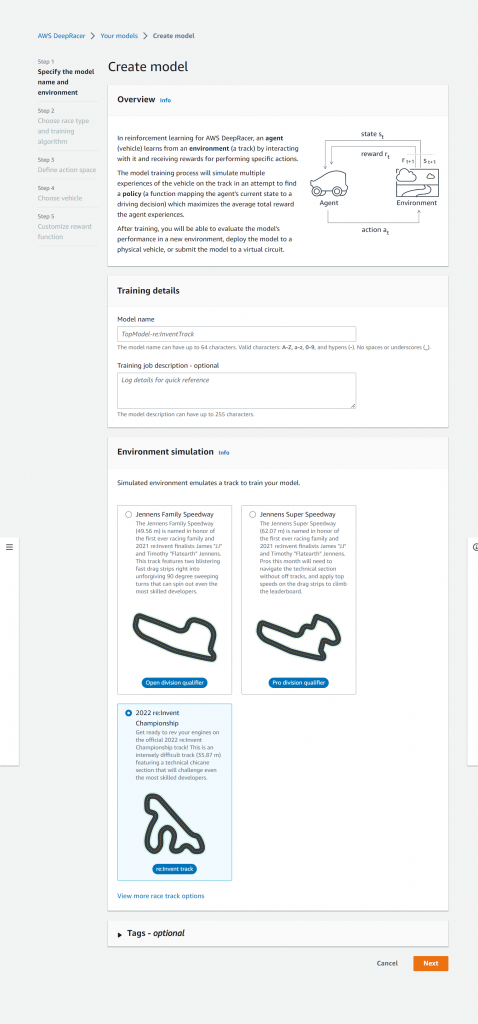
任意のモデル名と環境を選択します。
ここでいう環境の選択はどのコースでモデルをトレーニングするかを選択するかという意味になります。今回は2022 re:Invent Championshipを選択します。
レースの種類とトレーニングアルゴリズムの選択
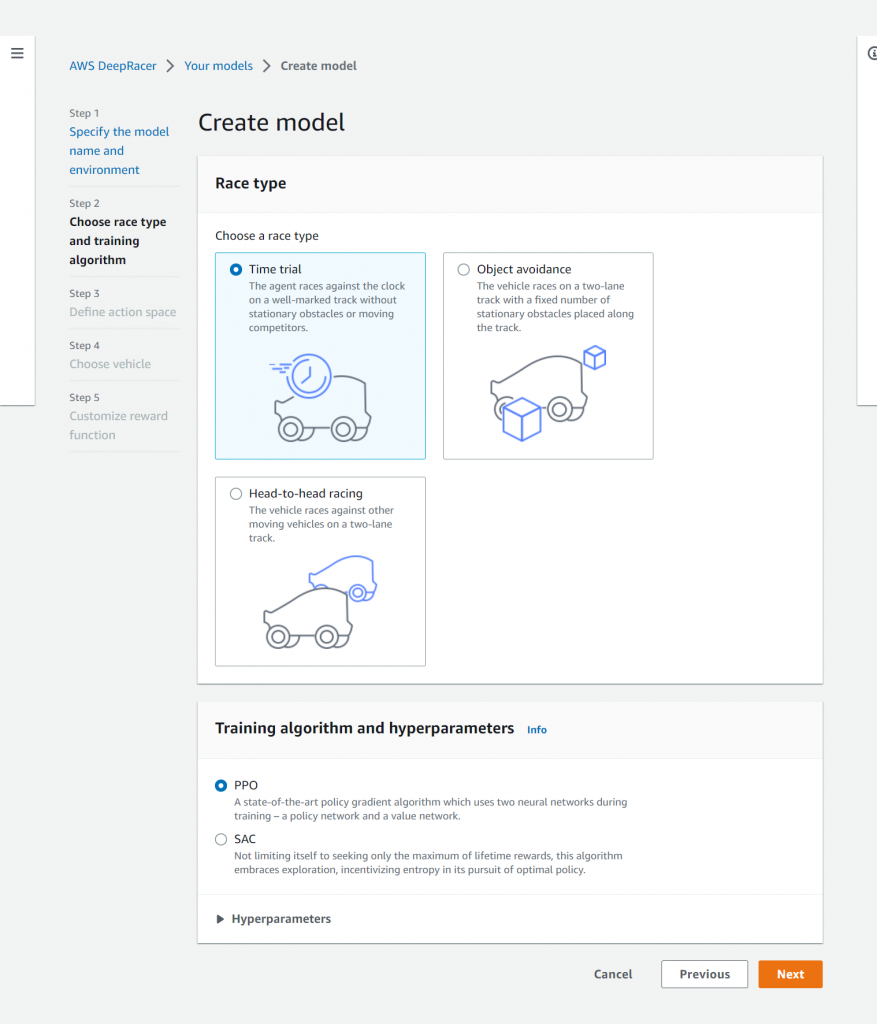
レースの種類をTime trial、Object avoidance、Head-to-head racingの中から選択し、トレーニングアルゴリズムをPRO、SACの中から選択します。
今回はそれぞれTime trial、PROを選択します。
アクションスペースの選択
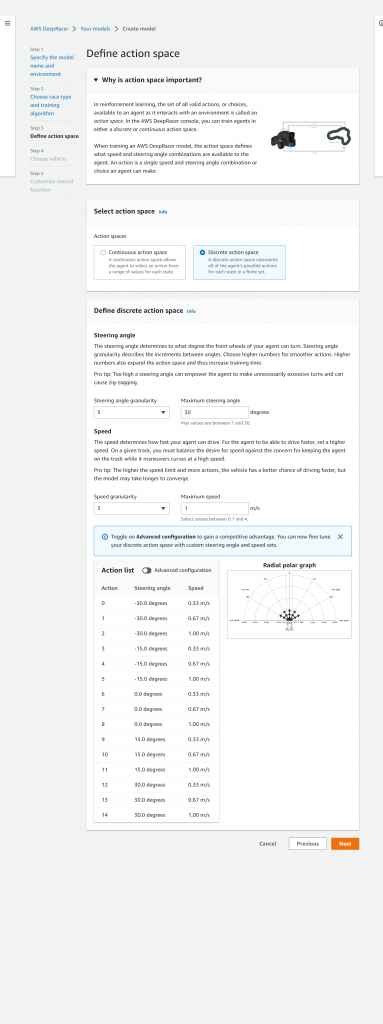
アクションスペースをContinuous action space、Discrete action spaceから選択します。
今回はDiscrete action spaceを選択します。
選択後、Steering angle granularit (ステアリングの角度)を5、Maximum steering angle(最大舵取り角度)を30 Speed granularity(速度の粒度)を2、Maximum speed(最大速度)を1に設定します。
車両シェルとセンサー構成の選択
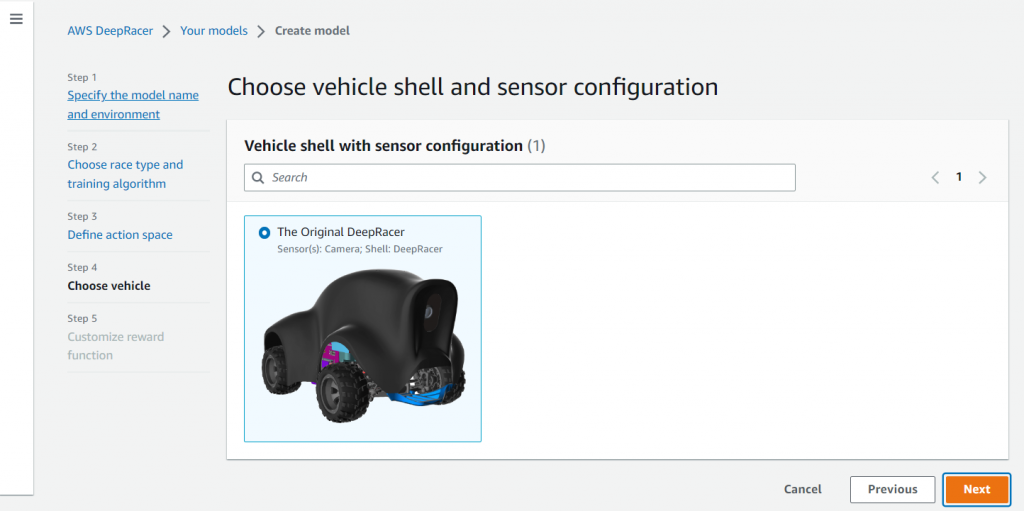
車両を選択します。筆者はデフォルトの車両しか存在しないためそちらを選択します。
報酬関数をカスタマイズ
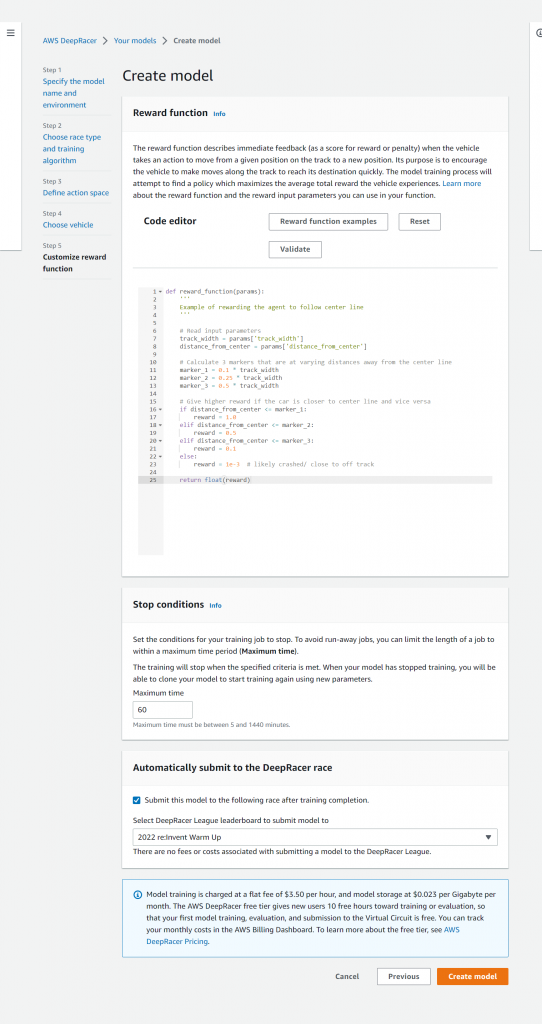
報酬関数とは機械学習における報酬、つまりアクションに対する報酬を返却する関数でありモデル作成のコアとなるものです。
今回はハンズオンなので最初から用意されている関数例から変更せずトレーニングしていきます。以下が実際に使用した関数です。
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
上記の通りこの関数はPython3を使用しています。
paramsのディクショナリに予めパラメータが用意されておりそちらを使用して定義していきます。上記の関数がコースのセンターラインからの距離が近いほどより大きな報酬を与えるように定義しています。
関数作成後にトレーニングの停止条件を指定します。時間は5~1410分から選択できます。このトレーニングは1時間あたり3.5ドルの利用料金が発生するため注意してください。
トレーニング完了後モデルをそのままレースに提出もできます。今回はトレーニング時間を60分に指定して実行します。
モデルのトレーニング
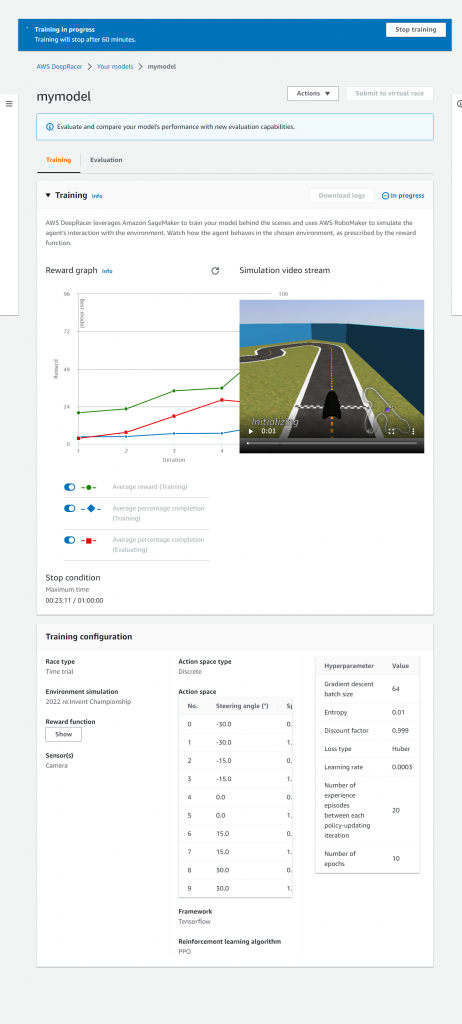
トレーニング開始後トレーニングしているAWS DeepRacerミニカーの様子を確認できます。作成した報酬関数のロジックに従いコースを進みながら学習されていきます。
モデルの評価
トレーニング完了後に作成されたモデルの評価を行います。
EvaluationタブからStart evaluationを選択後表示された画面で任意の評価名、レースの種類、評価の試行回数を選択します。今回、評価回数は3回で実施してみます。
評価結果確認
評価結果からコースを完走できたか、完走するまでにどれほどの時間がかかったかなどが記載されています。
また動画で仮想空間上のコースを走らせた様子を確認することができます。ここからモデルのクローンを行い報酬関数の調整を行いより理想的なモデルに近づけレースに挑戦、と言った流れになります。
現実世界のAWS DeepRacerコース
re:Invent会場にはAWS DeepRacer実機で実際のコースを走らせているサーキットがあります。
以下の画像はMGM Grand、Venetion EXPOのサーキットです。


まとめ
今回参加したセッションを通じて機械学習の初歩を学ぶことができました。
機械学習は理解するのが難しい印象もあるかもしれませんがAWS DeepRacerであればゲームのような感覚で理解することができわかりやすかったです。
またAWS DeepRacerは機械学習に興味をもつ人を増やすためのサービスでもあるとのことなので皆さんもぜひAWS DeepRacerを通じて機械学習の世界の扉をたたきにいきましょう!




