
Stackdriver を利用した Google Compute Engine の監視設定方法
2018.11.27
Google Cloud Platform で提供されているモニタリングサービスを利用して、仮想マシン(リソースとサービスプロセス)の監視設定をご紹介します。
はじめに
GCP(Google Cloud Platform)では、Stackdriver という監視サービスが提供されています。
このサービスを利用して、GCP で稼働するリソースや AWS(Amazon Web Services)で稼働するリソースからデータを収集し、そのデータを基にシステム監視の設定を行うことが可能です。
この記事では、Stackdriver を利用したGCE(Google Compute Engine)監視設定の方法をご紹介します。
なお、今回は Stackdriver Monitoring による監視設定を対象としており、Stackdriver Logging の監視設定は含まれておりません。
ご紹介させていただく手順については、以下の環境で実装した際の手順となります。
OS:CentOS 7.4
MW:Apache 2.4
GCE より外部インターネット環境への通信が可能

エージェントのインストール
GCE からデータを収集するためには、stackdriver-agent のインストールが必要となります。
(インストールしなくても、一部のデータは収集されています)
インストールは非常に簡単で、以下の通りです。
1.ホストにSSHでログインします。
2.エージェントインストールのインストールスクリプトをダウンロードするため、適当なディレクトリに移動します。
3.以下のコマンドを実行します
$ sudo curl -sSO https://dl.google.com/cloudagents/install-monitoring-agent.sh
$ sudo bash install-monitoring-agent.sh
$ systemctl status stackdriver-agent
※ステータスが active (running) になっていれば正常にインストールされています
Stackdriver の画面上でもデータが送信されるようになったことが確認できます。
リソースデータの監視設定
収集したデータを基に、システムが異常状態になった場合にアラート通知できるように設定を行います。
Stackdriver の画面左側のメニューから、以下の順番でアラートの設定画面に進みます。
[Alerting] → [Create a Policy]
アラートポリシーの設定画面が表示されますので、まずは [Conditions] から設定します。
[ADD CONDITION] をクリックすると設定画面に遷移します。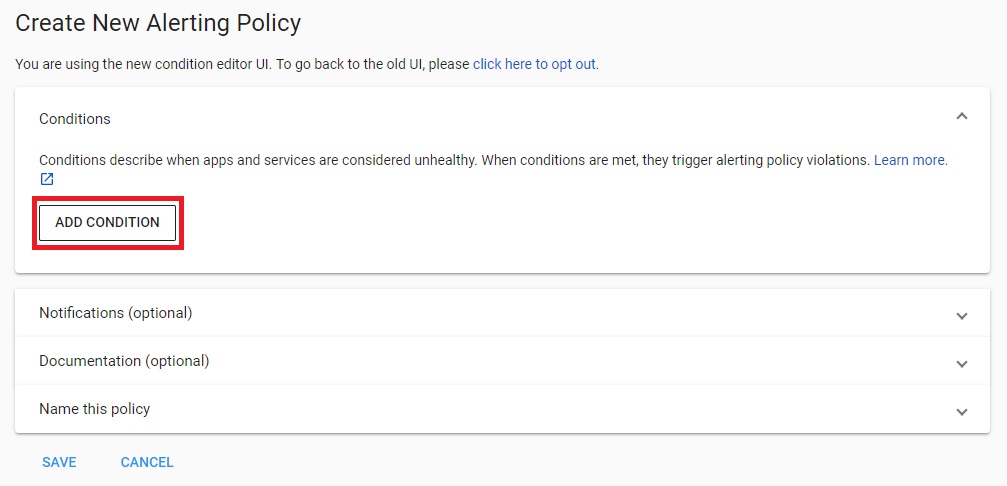
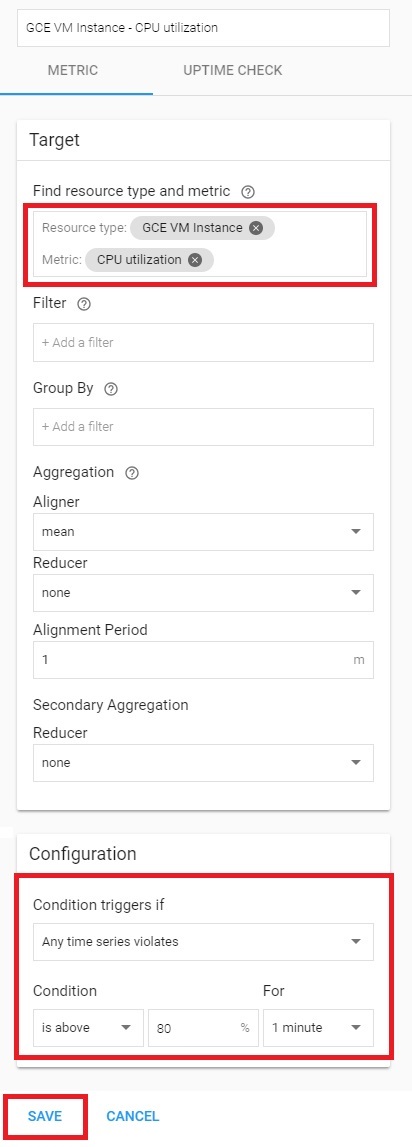
Condition を設定する画面では、ターゲットとなるリソースや基準となる閾値を設定します。
まずターゲットには、監視対象とするリソースを定義します。今回は GCE のリソースを監視しますので、[GCE VM Instance] を指定します。
指定すると、そのリソース上で収集しているデータの情報が表示されますので、監視したい項目を選択します。
なお、ターゲットにはフィルタをかけて絞り込んだり、複数リソースを統合した値で設定したりすることもできます。
(今回は単体での設定としますので、特に設定はしていません)
続いて、閾値となる [Configuration] を指定します。
ここで設定した基準値を上回る(または下回る)とアラートとして検知されます。
設定が完了したら、[SAVE] をクリックします。
Conditionに設定が追加されたことが確認できます。
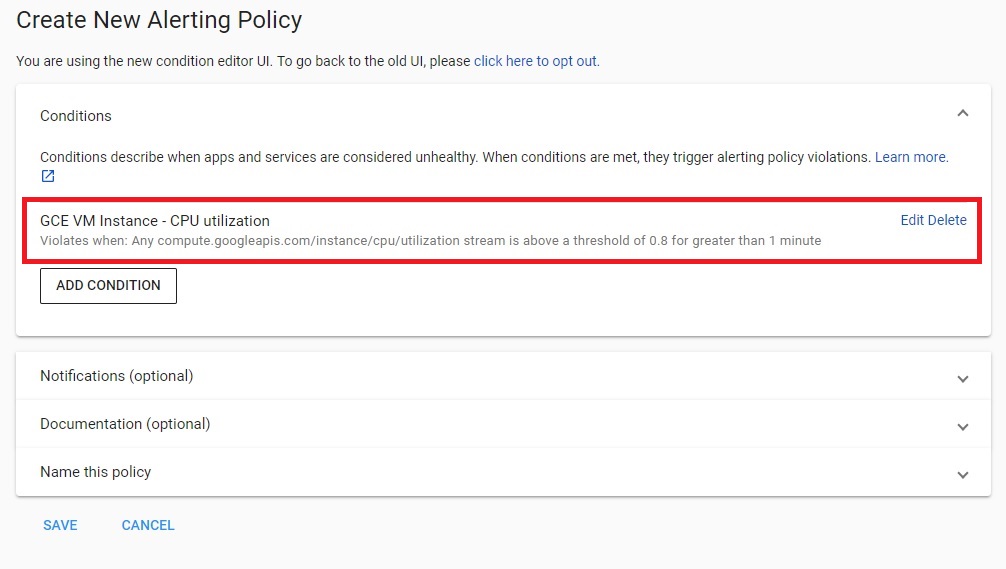
Notifications (optional) では、アラート検知した際の通知先を設定します。
通知の方法は以下となります。(事前にアカウント情報の設定が必要となる項目があります)
– E-mail
– SMS
– Google Cloud Console (mobile)
– HipChat
– Slack
– PagerDuty
– Webhook
– Campfire
目的に合わせて、通知設定を行います。
今回は E-mail でのアラート通知設定を行いました。
Documentation (optional) は、アラート通知した際に情報として追加表示される項目となります。
例えば、E-mail による通知を設定した場合には、ここで設定した内容がメールの本文に追記されます。
一見してどのような障害が発生したのかがわかるように、設定しておくことをオススメします。
最後にアラートの設定項目のポリシー名を設定し、[SAVE] をクリックすると、設定が完了となります。
設定完了すると、以下のような画面が表示されます。
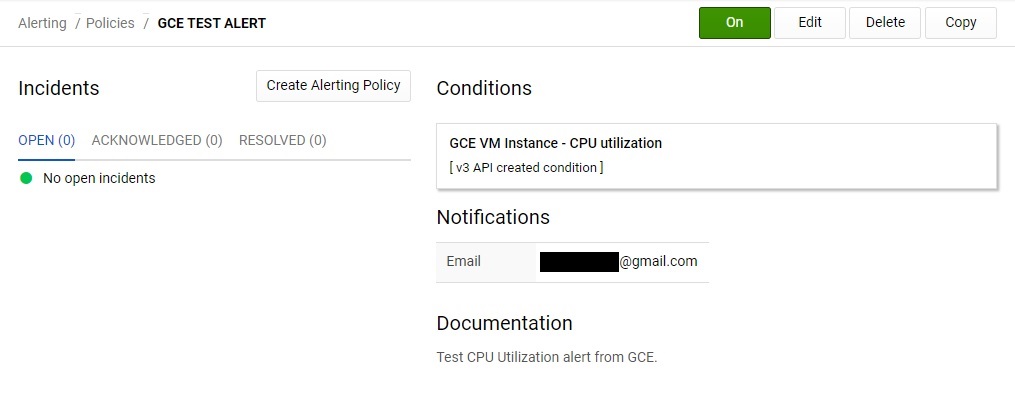
サービスプロセスの監視設定
次に、サービスプロセスがダウンした際に、それを検知できるように監視設定を行います。
今回は Apache のサービスプロセス監視の設定方法についてご紹介しますが、その他にも多くのサービスプロセス監視ができるように、設定ファイルが予め準備されています。
参考:サードパーティ製アプリケーションのモニタリング
上記リンク先にないサービスプロセスを監視したい場合は、ユーザーにてカスタム設定を行う必要があります。
Apache のデータ収集のため、設定ファイルの設定を行います。
まず、GitHub 構成リポジトリから status.conf をダウンロードし、VM インスタンス上の Apache の構成ディレクトリに置きます。
$ cd /etc/httpd/conf.d/ && sudo curl -O https://raw.githubusercontent.com/Stackdriver/stackdriver-agent-service-configs/master/etc/httpd/conf.d/status.conf
設定ファイルの読み込みのため、Apache を再起動します。
$ sudo systemctl restart httpd
$ systemctl status httpd
次に、Apache モニタリング プラグインを有効化します。
GitHub 構成リポジトリから apache.conf をダウンロードし、VM インスタンス上の /opt/stackdriver/collectd/etc/collectd.d 配下に置きます。
$ cd /opt/stackdriver/collectd/etc/collectd.d/ && sudo curl -O https://raw.githubusercontent.com/Stackdriver/stackdriver-agent-service-configs/master/etc/collectd.d/apache.conf
実は、status.conf と apache.conf での設定に差分があり、このまま設定を進めてもうまく監視ができません。
そのため、設定ファイルを修正します。
$ sudo vi apache.conf
→以下の修正を実施
変更前: URL “http://:80/server-status?auto”
変更後: URL “http://local-stackdriver-agent.stackdriver.com:80/server-status?auto”
設定ファイルの読み込みのため、stackdriver-agent を再起動します。
$ sudo systemctl restart stackdriver-agent
$ systemctl status stackdriver-agent
プラグインが有効化されたことを確認します。
$ curl http://local-stackdriver-agent.stackdriver.com:80/server-status?auto
以下のような表示がされれば有効化されています。
local-stackdriver-agent.stackdriver.com
ServerVersion: Apache/2.4.xx ・・・
最後に、Stackdriver の画面より、アラート通知設定を行います。
リソースデータの監視設定で実施した際と同様に、アラートのポリシーを作成します。
今回は Apache のプロセスがなくなった場合にアラートとなるよう、[Metric] に [Open connections] を指定し、判断基準となる [Condition] に [is absent] を指定しました。
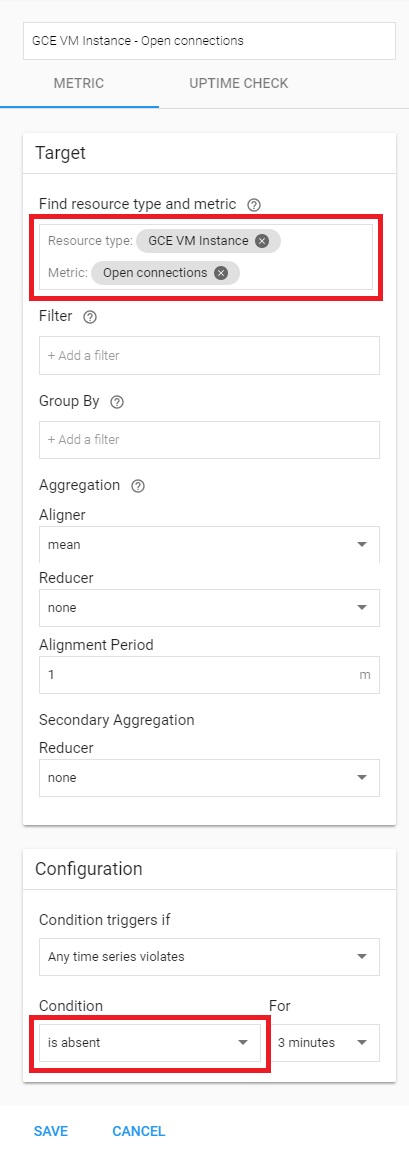
設定完了後は以下のような画面が表示されます。
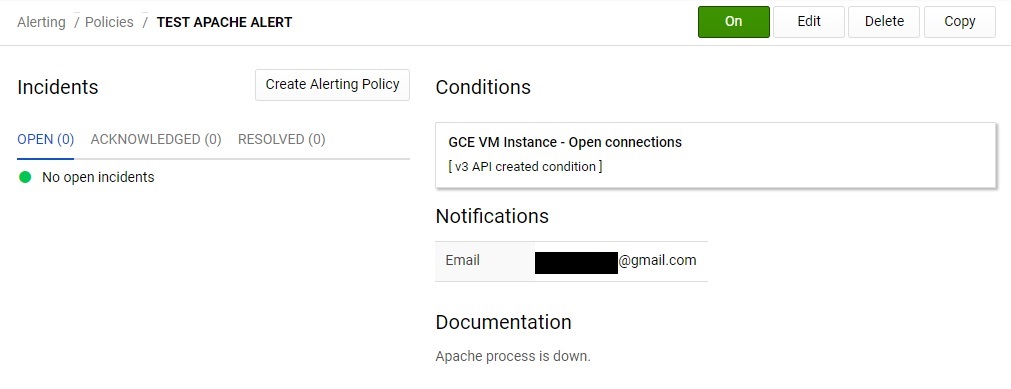
アラート通知確認
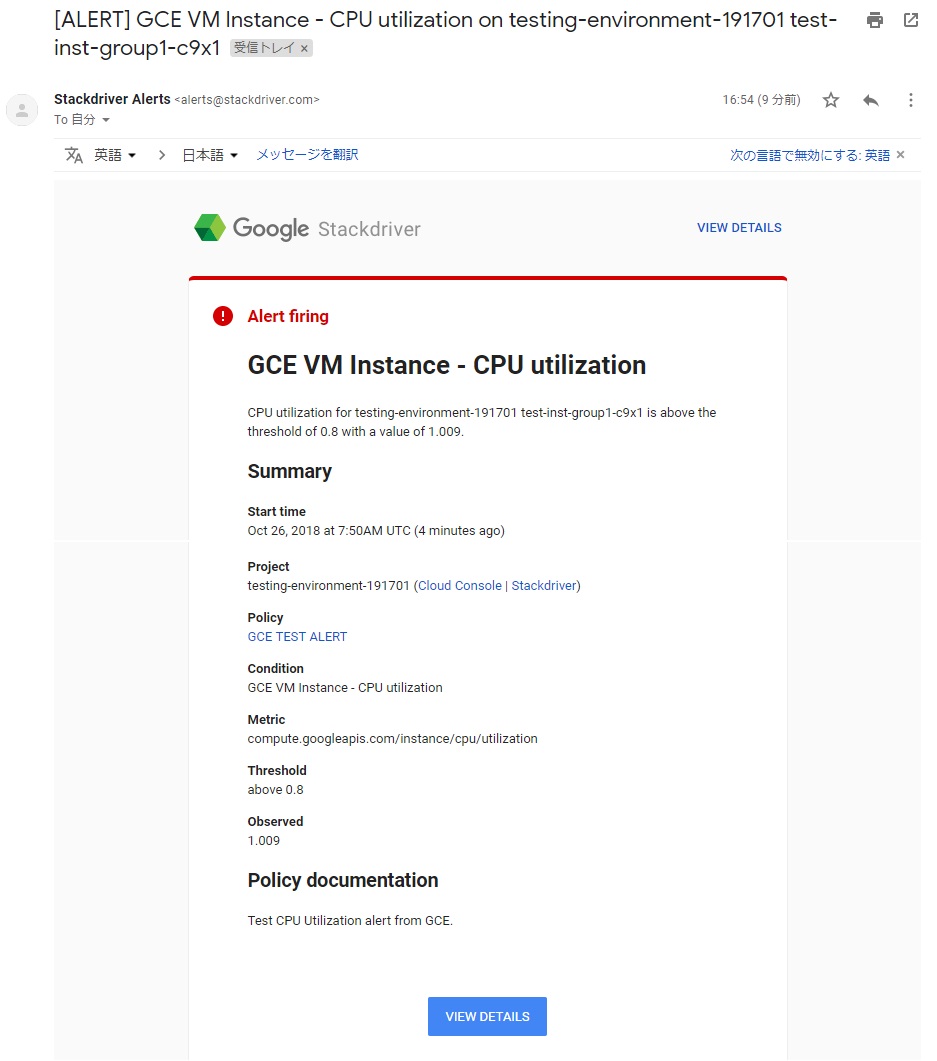
早速コマンドラインで実際にサーバーに負荷をかけて、設定したしきい値を超過した環境を作ってみます。
一定時間以上、高負荷状態にしていると、アラートメールが届きました。

アラートの本文は以下のような表示となります。
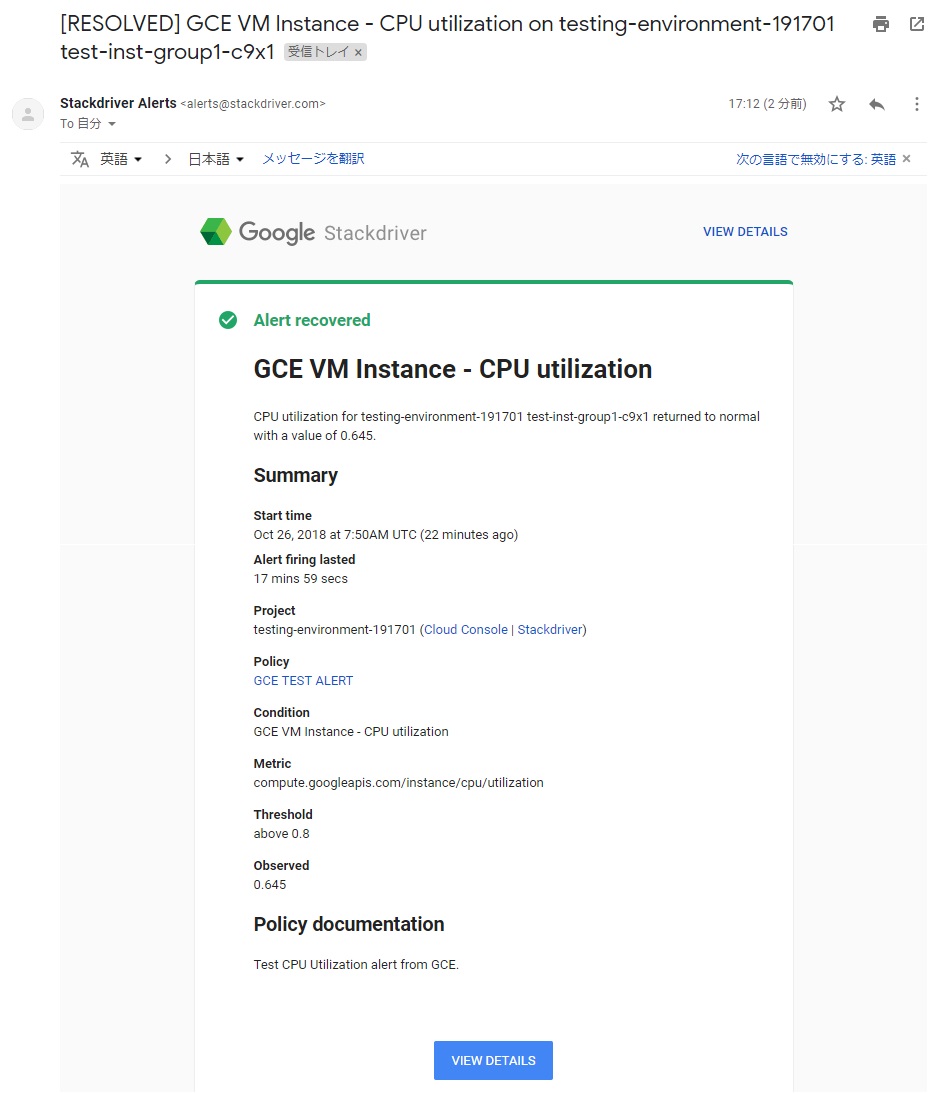
アラート状態が解消されると、[Resolve] でのメールが届きます。

解消した際の本文は以下の表示となります。
続いて、Apache のプロセスを停止してみます。
こちらも一定時間以上、停止の状態にしているとアラートが届きました。(メール本文は省略します)

サービスプロセスを起動して少し待つと、[Resolve] でのメールが届きます。

おわりに
ご紹介させていただいた通り、Stackdriver Monitoring を使うことで、とても簡単に GCE のリソースやサービスプロセスのエラー状態を検知する設定が可能です。
今回ご紹介しきれませんでしたが、Stackdriver Monitoring で取得しているデータであれば、同様に監視の設定を行うこともできますので、是非設定にチャレンジしていただければと思います。




