
Amazon Kinesis Data Streamsを利用して、大量のデータをリアルタイムに高速で処理する方法
2022.10.19
Amazon Kinesis Data Streamsとは、リアルタイムに送信される大量のデータを扱うことができるサービスです。
本記事ではAmazon Kinesis Data Streamsで受け取ったデータをLambdaで処理し、DynamoDBに格納することを例として、Amazon Kinesis Data Streamsの利用方法をご紹介いたします。
はじめに
アプリケーションやIoT機器などを開発・運用している皆様の中で、大量のログやセンサーのデータなどを高速に収集、保存、分析する方法に悩んでいる方も多いと思います。
そこで今回は、Amazon Web Services(以下、AWS)のサーバーレスストリーミングデータサービスであるAmazon Kinesis Data Streams(以下、Kinesis Data Streams)のご紹介と、実際の利用方法を解説します!
記事前半ではKinesis Data Streamsの概要を、後半ではKinesis Data Streamsの利用方法をお伝えするので、是非じっくりとご覧ください。
Amazon Kinesis Data Streamsの概要
まず、Kinesis Data Streamsの概要についてお伝えします。
Kinesis Data StreamsとはWebサービスやアプリケーションのログ、IoT機器のセンサーデータなど絶え間なく送信されてくるストリーミングデータをリアルタイムに収集、保存、分析することができるサーバーレスのサービスです。WebサービスやIoT機器から送信されるデータをKinesis Data Streamsが受け止め、他のAWSサービスがKinesis Data Streamsからデータを読み出して利用します。並列処理が可能であり、大量のデータに対して高速な処理を行うことができます。
Amazon Kinesis Data Streamsを利用するメリット
Kinesis Data Streams の概要についてご理解いただいたところで、Kinesis Data Streamsを利用するメリットについてご紹介します。
1. 遅延が少ない
Kinesis Data Streamsでは、送信されたデータが利用可能になるまでの時間が1秒未満と非常に短いです。データをリアルタイムで処理することができるため、素早いデータ利用が可能となります。
2. 管理が容易
処理しなければならないデータの量が大きく変化した場合、Kinesis Data Streamsの処理リソース単位である“シャード”の数を管理画面から増減させることで簡単にスケーリングができます。アクセスの集中などによりデータ量が増大しても、シャードを増やすだけで対応できます。
3. 複数のアプリケーションから利用可能
Kinesis Data Streamsが受け取ったデータはデフォルトで24時間(設定により最大1年)保存されます。これらのデータはAWSの各サービスなどの複数のアプリケーションから同時にアクセスすることができます。リアルタイムなデータ処理だけでなく、日毎のデータ処理などにもKinesis Data Streamsがそのまま利用できます。
Amazon Kinesis Data Streamsの利用方法
では、実際にKinesis Data Streamsを利用してみましょう。
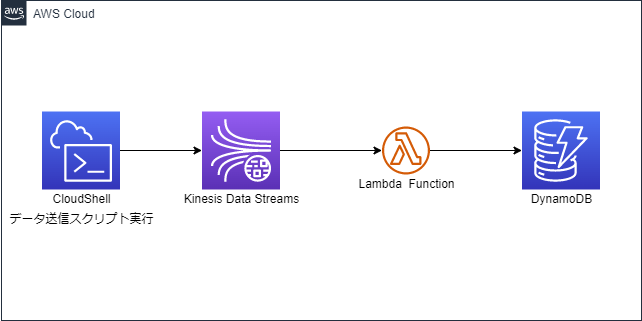
今回は、AWS CloudShell(以下、CloudShell)からKinesis Data Streamsにデータを送信し、AWS Lambda(以下、Lambda)でデータを処理します。処理したデータをAmazon DynamoDB(以下、DynamoDB)に格納します。今回は、架空の室温計IoTを想定したスクリプトをCloudShell上で実行します。構成図は以下のようになります。
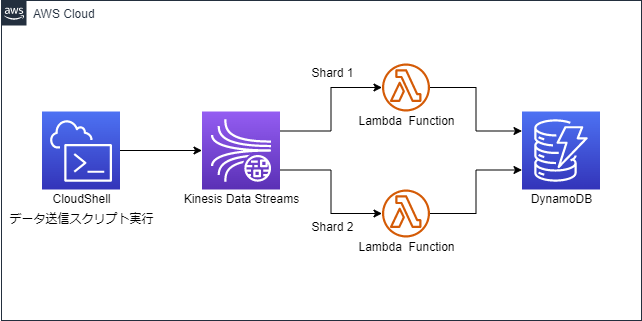
実装方法
IAMでロールを作成
AWS Identity and Access Management(以下、IAM)にて、使用するAWSのサービス同士がアクセスできるようにロールを作成します。今回は、Kinesis Data Streams、Lambda、DynamoDBを使用するため、下記のポリシーをアタッチしたロールを「test_kinesis_lambda_role」という名称で作成します。
Kinesisでデータストリームを作成
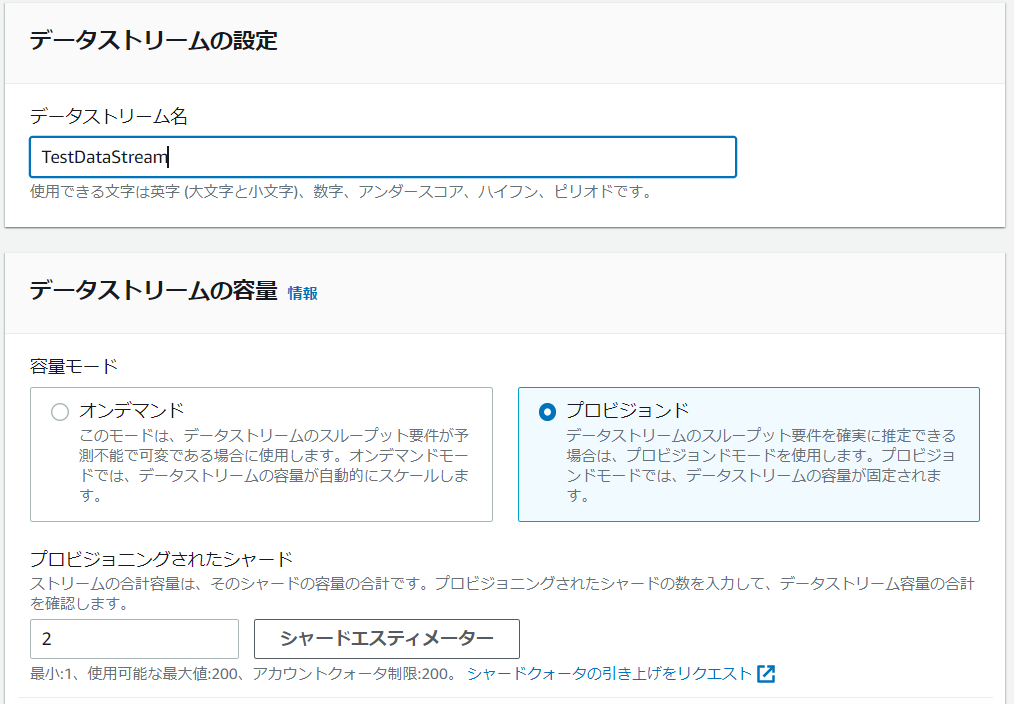
AWSマネジメントコンソールのサービス:「Kinesis」で「Kinesis Data Streams」を選択して「データストリームを作成」から新規データストリームを作成します。

データストリームの作成画面で以下のように設定し、「データストリームの作成」を選択します。
▶️プロビジョニングされたシャード:2
DynamoDBでテーブルを作成
AWSマネジメントコンソールのサービス:「DynamoDB」で「テーブルの作成」を選択します。
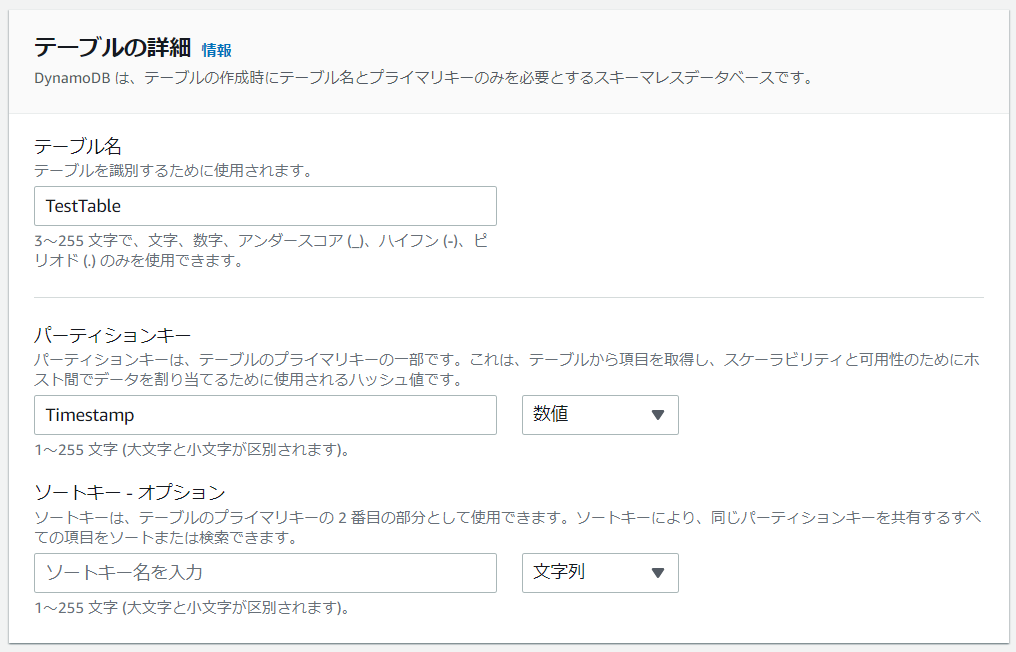
テーブルの作成画面で以下のように設定し、「テーブルの作成」を選択します。
▶️パーティションキー名:Timestamp
▶️種類:数値
Lambdaで関数を作成
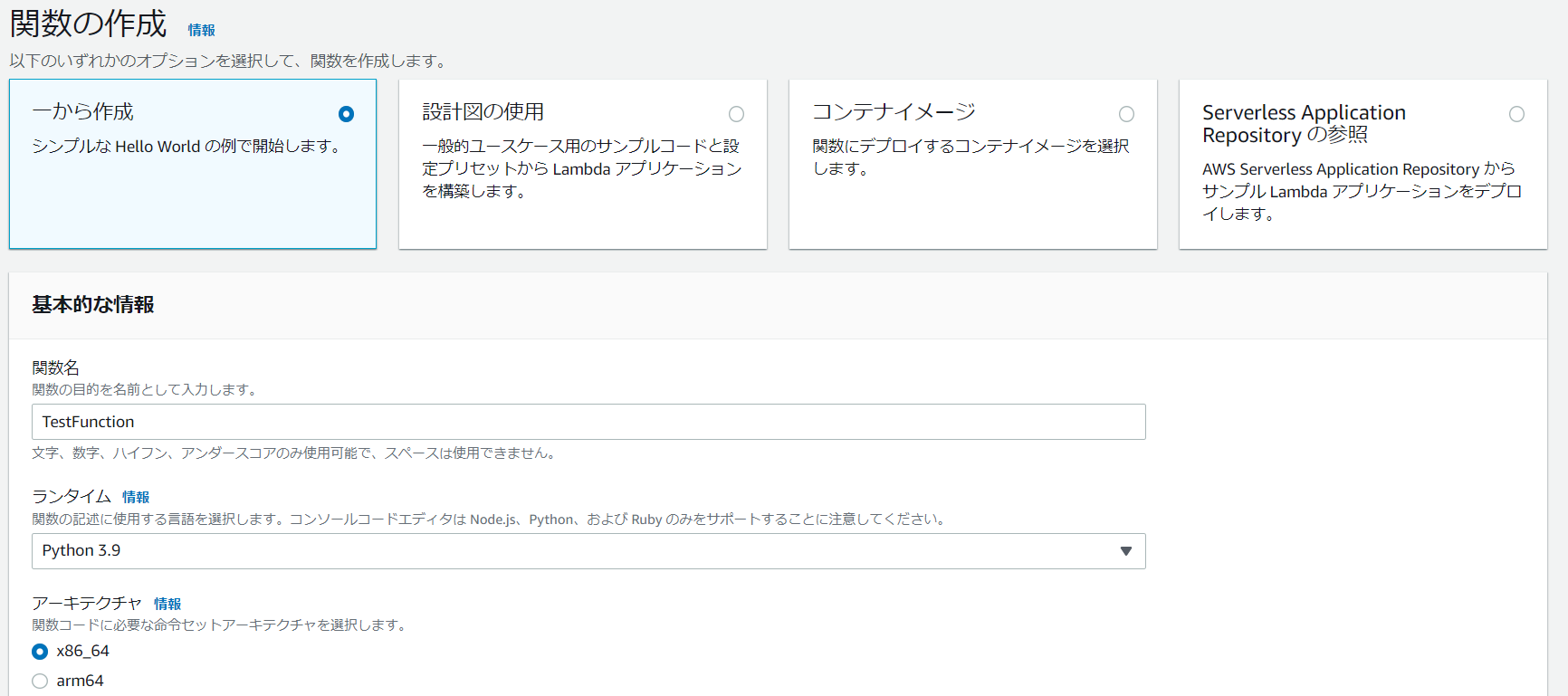
AWSマネジメントコンソールのサービス:「Lambda」で「関数の作成」を選択します。
関数の作成画面で以下のように設定し、「関数の作成」を選択します。
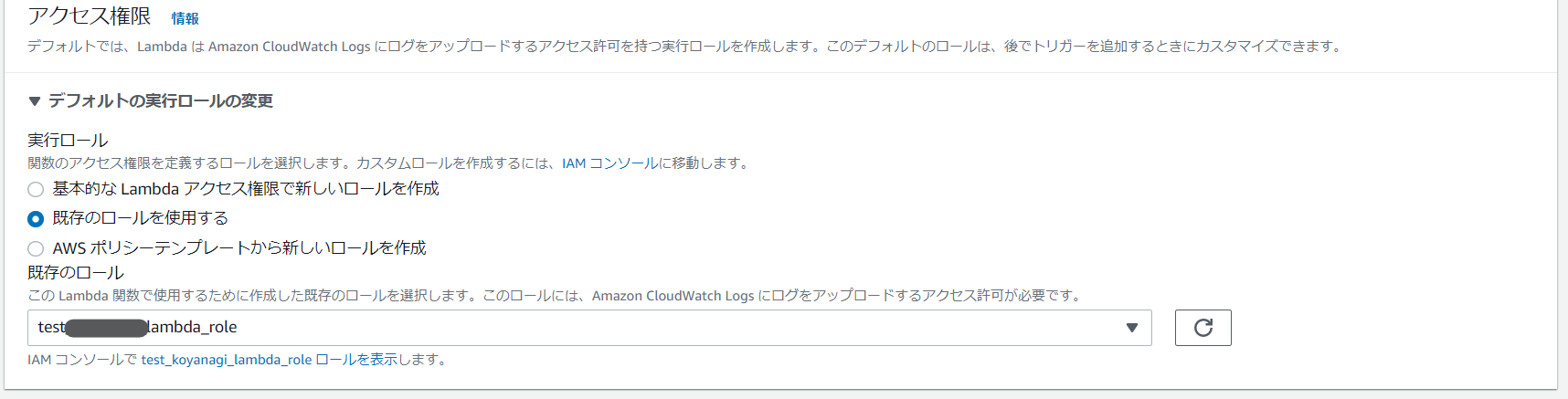
▶️実行ロール:既存のロールを使用する→「test_kinesis_lambda_role」を選択
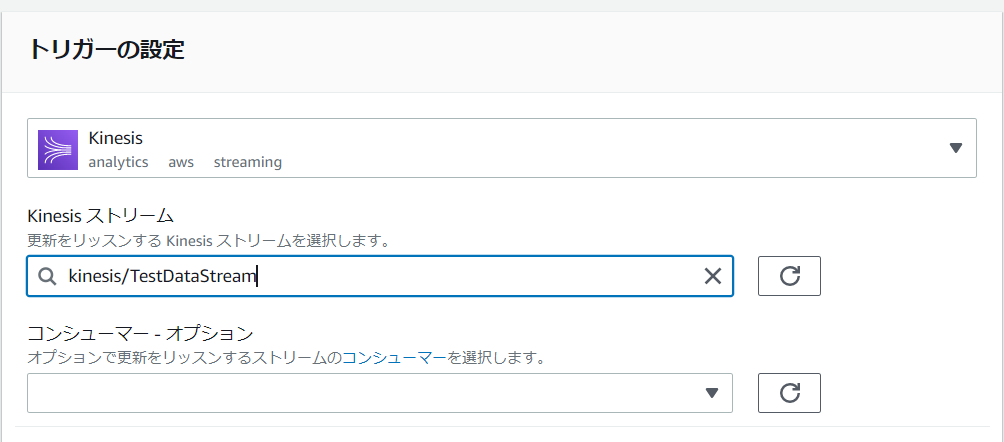
「TestFunction」の管理画面で、「トリガーを追加」を選択します。トリガーを追加の画面で以下のように設定し「追加」を選択します。
「TestFunction」の「コード」タブを選択し、コードソース内の「lambda_function.py」を以下のように変更し、「Deploy」を選択します。
import json
import base64
import boto3
TABLE_NAME = "TestTable"
table = boto3.resource("dynamodb").Table(TABLE_NAME)
def lambda_handler(event, context):
for record in event["Records"]:
payload = base64.b64decode(record["kinesis"]["data"])
data = json.loads(payload)
print(data)
if data["Temperature"] >= 35:
res = table.put_item(
Item=data
)
print(res)
return f"Successfully processed {len(event['Records'])} records."
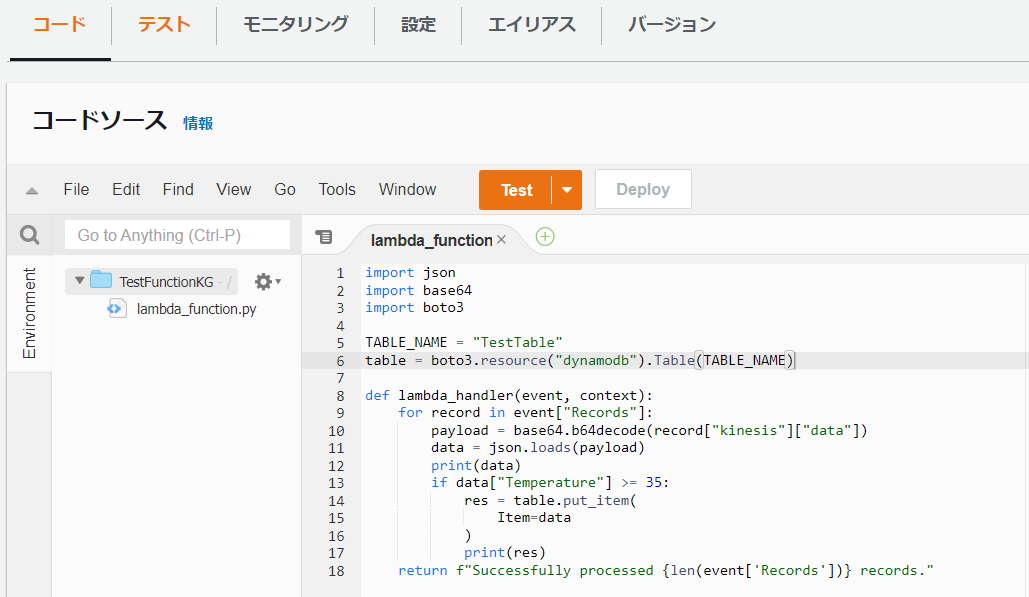
このスクリプトは、Kinesis Data Streamsで作成したデータストリーム「TestDataStream」がデータを受け取るたびに実行されます。受け取ったデータの”Temperature”が35以上であるデータだけをDynamoDBで作成したテーブル「TestTable」に保存します。
データ送信スクリプトの作成
実際に利用する際にはアプリケーションやIoT機器などがデータをデータストリームに送信しますが、今回は作成するPythonスクリプトからデータを送信します。
AWSマネジメントコンソールのサービス:「AWS CloudShell」を使用します。
$ vim send_stream_data.py
と実行し、以下のスクリプトを作成します。
import boto3
import json
import random
import string
import datetime
import time
import pprint
STREAM_NAME = "TestDataStream"
kinesis = boto3.client("kinesis")
def make_data():
data = {}
now = datetime.datetime.now()
data["Timestamp"] = int(now.timestamp() * 1000)
data["Spot"] = random.choice(list(string.ascii_uppercase))
data["Temperature"] = random.randint(10, 40)
return data
if __name__ == "__main__":
i = 0
start = time.time()
while i < 100:
data = json.dumps(make_data())
p_key = str(random.randint(1, 100))
res = kinesis.put_record(
StreamName=STREAM_NAME,
Data=data,
PartitionKey=p_key
)
print(data)
print("p_key : ", p_key)
pprint.pprint(res)
i += 1
print(f"{i} items sent")
print(f"time : {time.time()-start}")
このスクリプトは、架空のIoT機器を想定し、時刻”Timestamp”, 設置場所”Spot”, 気温”Temperature”を持ったデータを「TestDataStream」に送信します。PartitionKeyは、どのシャードにデータを送信するかを決めるものです。
PartitionKeyはシャード数より十分多い種類でないと、適切にデータが分配されません。データの送信が行われると、どのシャードがデータを受け取ったかなどの情報を持つレスポンスを出力します。
データの送信と確認
スクリプトの保存後、
$ python3 send_stream_data.py
と実行し、データをデータストリームに送信します。10秒ほどで実行が完了します。
シャード数が2に設定されているため、’ShardId’に2種類のIDが確認できると思います。
データの処理が行われたか、先ほど作成したDynamoDBのテーブルを確認します。「テーブルアイテムの探索」を選択します。「アイテムのスキャン/クエリ」の「実行する」を選択します。
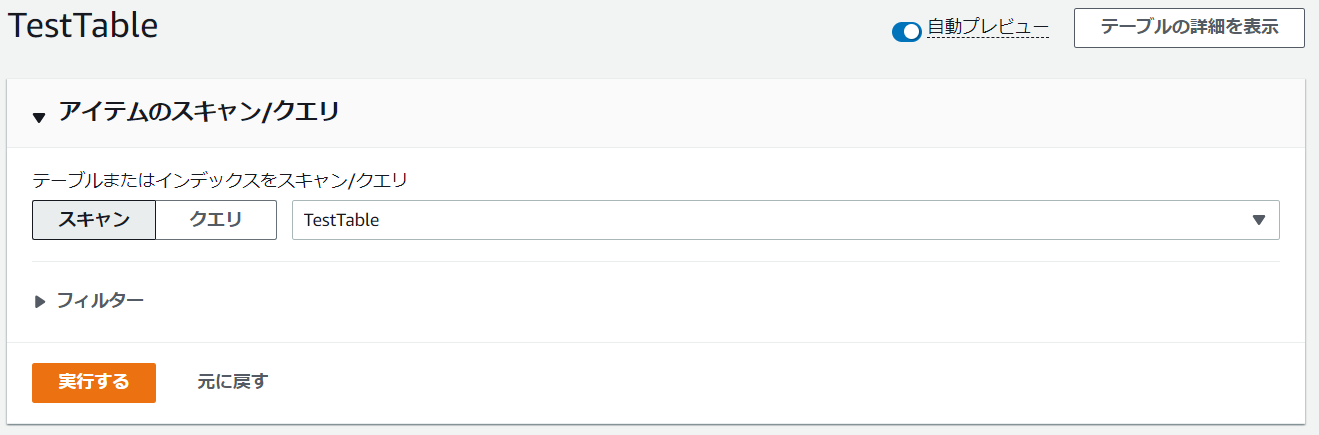
実行後、「返された項目」にいくつかのデータがあると思います。これでデータの処理ができていることが確認できました!
シャード数の変更
今回のスクリプトは1秒間に十数個のデータ送信であるため、Kinesis Data Streamsの性能(1秒間におよそシャード数×1000個)にはまだまだ余裕があります。シャード数が2である必要がないため、減らしてみようと思います。変更後の構成図は以下のようになります。
「TestDataStream」の設定から、「プロビジョニングされたシャードを編集」を選択します
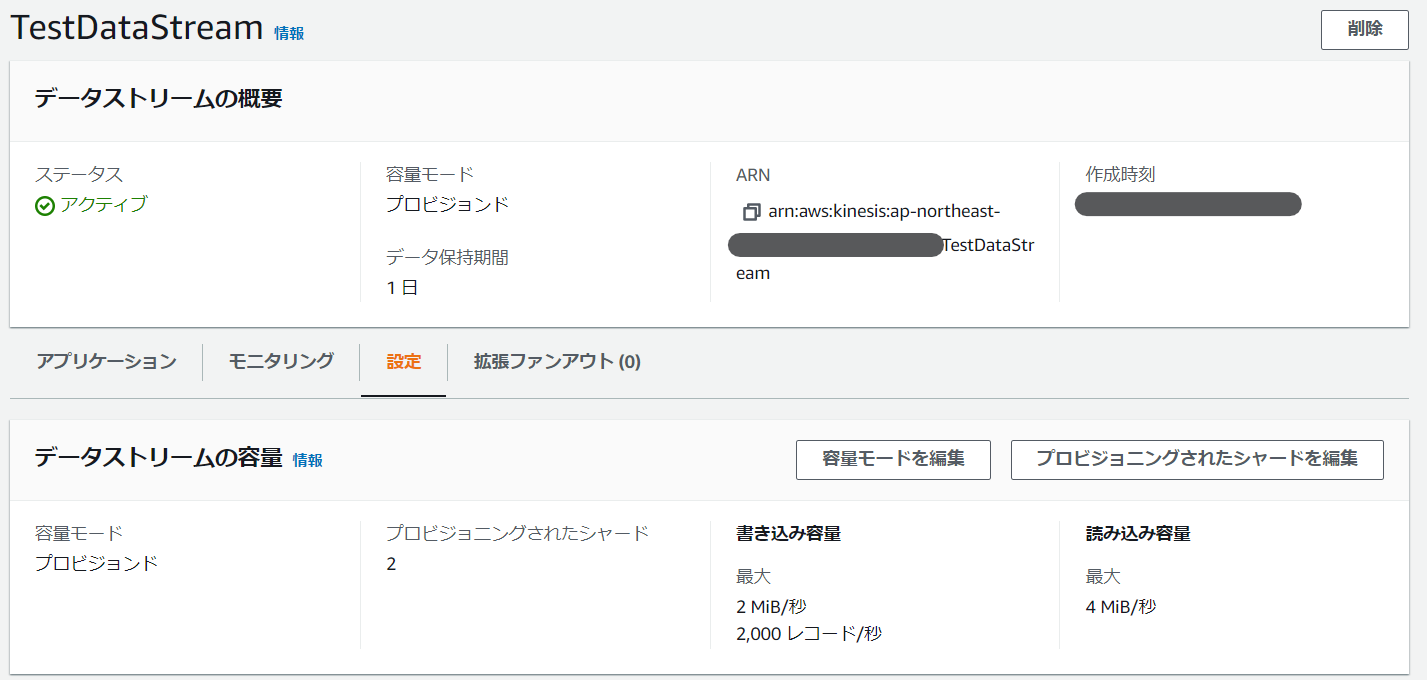
「プロビジョニングされたシャード」を1に変更し、「変更を保存」を選択します。
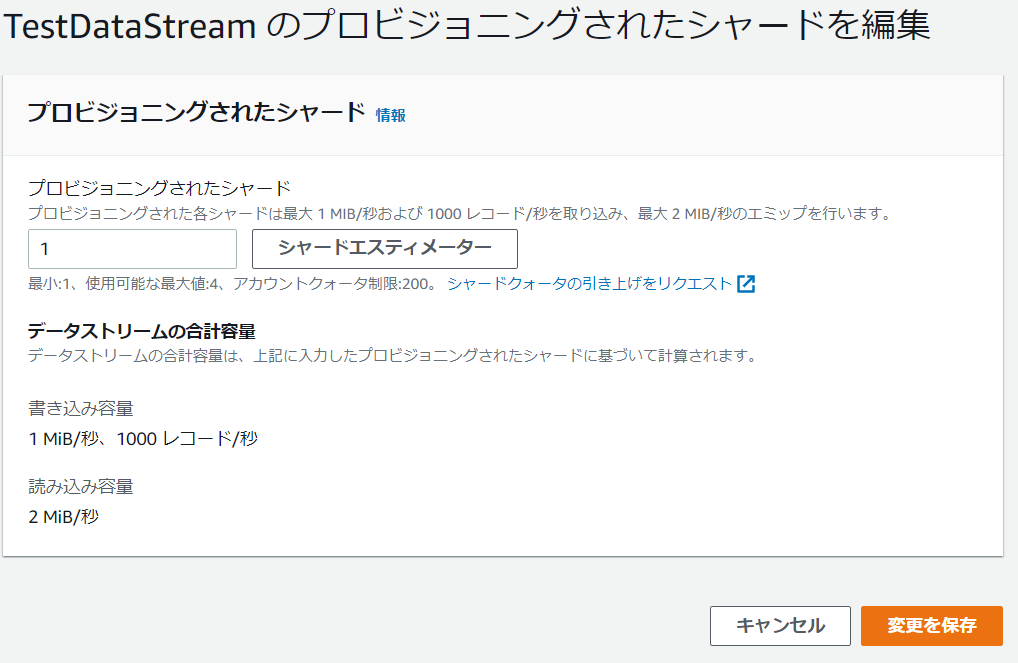
シャード数の変更には数分かかることがあります。
変更の完了後、CloudShellに戻り、もう一度
$ python3 send_stream_data.py
を実行します。すると先ほどとは異なり、’ShardId’が1種類になったことが確認できると思います。このようにKinesis Data Streamsでは、必要な性能に応じて容易にシャード数を変更できます。
まとめ
本記事は、Amazon Kinesis Data Streamsの概要とAmazon Kinesis Data Streamsを利用してデータを処理する方法をご紹介しました。今回は架空のIoT機器を想定したスクリプトをCloudShell上で実行しましたが、もちろん実際のIoT機器で送受信される大量のデータに対しても、シャードを増減させることで簡単にスケーリングすることができます。
その他に、リアルタイム性が重要視されるアプリケーションや複数のアプリケーションからデータを送受信する必要がある場合などにも活用できるかと思いますのでぜひ、皆様のシステムにもAmazon Kinesis Data Streamsの導入を検討してみてはいかがでしょうか。




